


We all know that we should avoid index and table scans like the plague and try to get an index seek all the time.
Okay, what will happen if we fill a table with one million rows that have the same exact value and then create a clustered index on it.
Yes, you can create a clustered index on a non unique column because SQL Server will create a uniquefier on that column to make the index unique.
Create the following table with a clustered index
create table TestIndex (Value varchar(100) not null)
create clustered index ix_TestIndex on TestIndex(Value)
Now insert a million rows with all the same value
insert TestIndex
select top 1000000 'A' from master..spt_values s1
CROSS JOIN master..spt_values s2
Now run the following and look at the execution plan
select count(*) from TestIndex
where Value = 'A'
select count(*) from TestIndex
Here is what the plan looks like.
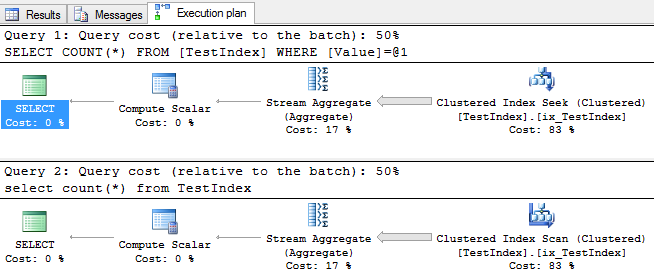
Here is what the plan looks like in text (you can get the output if you run SET SHOWPLAN_TEXT on first)
_|–Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1005],0)))
|–Stream Aggregate(DEFINE:([Expr1005]=Count(*)))
|–Clustered Index Seek(OBJECT:([Test].[dbo].[TestIndex].[ix_TestIndex]),
SEEK:([Test].[dbo].[TestIndex].[Value]=[@1]) ORDERED FORWARD)
|–Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1005],0)))
|–Stream Aggregate(DEFINE:([Expr1005]=Count(*)))
|–Clustered Index Scan(OBJECT:([Test].[dbo].[TestIndex].[ix_TestIndex]))
What about IO, is that any different?
set nocount on
set statistics io on
select count(*) from TestIndex
where Value = 'A'
select count(*) from TestIndex
set statistics io off
_Table ‘TestIndex’. Scan count 1, logical reads 2491, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘TestIndex’. Scan count 1, logical reads 2491, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Looks the same to me
Now let’s take a look at the time it takes to run this
set nocount on
set statistics time on
select count(*) from TestIndex
where Value = 'A'
select count(*) from TestIndex
set statistics time off
Here is the output for that
_SQL Server Execution Times:
CPU time = 110 ms, elapsed time = 115 ms.
SQL Server Execution Times:
CPU time = 93 ms, elapsed time = 106 ms.
BTW, you will also get an index seek if you specify a WHERE clause like this
select count(*) from TestIndex
where Value > ''
So there you have it, a seek is not always faster than a scan. And yes, I know that this is a silly example
Okay just for fun now let’s insert another million rows with the value B
insert TestIndex
select top 1000000 'b' from master..spt_values s1
CROSS JOIN master..spt_values s2
And now run this
select count(*) from TestIndex
where Value in( 'A','B')
select count(*) from TestIndex
You will see almost the same exact behaviour as before, a seek for the statement with the WHERE caluse and a scan for the statament without the WHERE clause.
The difference between before and now is that parallelism is being used as you can see in the plan below

Here is the text version of the execution plan
_|–Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[globalagg1006],0)))
|–Stream Aggregate(DEFINE:([globalagg1006]=SUM([partialagg1005])))
|–Parallelism(Gather Streams)
|–Stream Aggregate(DEFINE:([partialagg1005]=Count(*)))
|–Clustered Index Seek(OBJECT:([Test].[dbo].[TestIndex].[ix_TestIndex]),
SEEK:([Test].[dbo].[TestIndex].[Value]=‘A’ OR [Test].[dbo].[TestIndex].[Value]=‘B’) ORDERED FORWARD)
|–Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[globalagg1006],0)))
|–Stream Aggregate(DEFINE:([globalagg1006]=SUM([partialagg1005])))
|–Parallelism(Gather Streams)
|–Stream Aggregate(DEFINE:([partialagg1005]=Count(*)))
|–Clustered Index Scan(OBJECT:([Test].[dbo].[TestIndex].[ix_TestIndex]))
If we set the max degree of parallelism to 1 by using the MAXDOP option we get the same plan as before
select count(*) from TestIndex
where Value = 'A'
option(maxdop 1)
select count(*) from TestIndex
option(maxdop 1)
Here is the graphical plan

Here is the text version of the plan
_|–Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1005],0)))
|–Stream Aggregate(DEFINE:([Expr1005]=Count(*)))
|–Clustered Index Seek(OBJECT:([Test].[dbo].[TestIndex].[ix_TestIndex]),
SEEK:([Test].[dbo].[TestIndex].[Value]=‘A’) ORDERED FORWARD)
|–Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1007],0)))
|–Stream Aggregate(DEFINE:([Expr1007]=Count(*)))
|–Clustered Index Scan(OBJECT:([Test].[dbo].[TestIndex].[ix_TestIndex]))
So there you have it, nothing earth-shattering in this post but still nice to know that a seek is not always faster than a scan
*** If you have a SQL related question try our Microsoft SQL Server Programming forum or our Microsoft SQL Server Admin forum
 Denis has been working with SQL Server since version 6.5. Although he worked as an ASP/JSP/ColdFusion developer before the dot com bust, he has been working exclusively as a database developer/architect since 2002. In addition to English, Denis is also fluent in Croatian and Dutch, but he can curse in many other languages and dialects (just ask the SQL optimizer) He lives in Princeton, NJ with his wife and three kids.
Denis has been working with SQL Server since version 6.5. Although he worked as an ASP/JSP/ColdFusion developer before the dot com bust, he has been working exclusively as a database developer/architect since 2002. In addition to English, Denis is also fluent in Croatian and Dutch, but he can curse in many other languages and dialects (just ask the SQL optimizer) He lives in Princeton, NJ with his wife and three kids.

