


In my Are you ready for SQL Server 2012 or are you still partying like it is 1999? post, I wrote about how you should start using SQL Server 2005 and SQL Server 2008 functionality now in order to prepare for SQL Server 2012. I still see tons of code that is written in the pre 2005 style and people still keep using those functions, procs and statements even though SQL Server 2005 and 2008 have much better functionality.
In today’s post I will cover partitioning. In the SQL Server 2000 days we called this horizontal partitioning, it is actually something I have implemented with great success when I started at my current job. Fragmentation was a non issue anymore because the way I have set up the tables the inserts didn’t fragment the tables anymore. Index rebuilds were also much faster since the tables were smaller and I could rebuild more than one table at the same time.
In this post I will show you how you do partitioning in SQL Server 2000 (partitioned views) and how you do it in 2005 and up. You might ask yourself why I waste my time showing you the 2000 version. This is because partitioning only works in the enterprise edition of SQL Server, if you are on the standard edition then you cannot use native partitioning. You can however still use partitioned views.
Partitioning the SQL Server 2000 way
In order to show you how to do this, we need to first create a bunch of tables. We will create a table for each year.
CREATE TABLE Sales2007 (YearCol SMALLINT NOT NULL,OrderID INT NOT NULL, SomeData UNIQUEIDENTIFIER DEFAULT newsequentialid())
GO
CREATE TABLE Sales2008 (YearCol SMALLINT NOT NULL,OrderID INT NOT NULL, SomeData UNIQUEIDENTIFIER DEFAULT newsequentialid())
GO
CREATE TABLE Sales2009 (YearCol SMALLINT NOT NULL,OrderID INT NOT NULL, SomeData UNIQUEIDENTIFIER DEFAULT newsequentialid())
GO
We will now insert some data into these tables
INSERT Sales2007(YearCol,OrderID)
SELECT 2007,number
FROM master..spt_values
WHERE type = 'P'
INSERT Sales2008(YearCol,OrderID)
SELECT 2008,number + 2048
FROM master..spt_values
WHERE type = 'P'
INSERT Sales2009(YearCol,OrderID)
SELECT 2009,number + 4096
FROM master..spt_values
WHERE type = 'P'
It is time to make our tables –CELKO– approved by adding primary keys
ALTER TABLE dbo.Sales2007 ADD CONSTRAINT
PK_Sales2007 PRIMARY KEY CLUSTERED (YearCol,OrderID)
ALTER TABLE dbo.Sales2008 ADD CONSTRAINT
PK_Sales2008 PRIMARY KEY CLUSTERED (YearCol,OrderID)
ALTER TABLE dbo.Sales2009 ADD CONSTRAINT
PK_Sales2009 PRIMARY KEY CLUSTERED (YearCol,OrderID)
Here is a view that will have all the tables in them
CREATE VIEW Sales
AS
SELECT * FROM Sales2007
UNION ALL
SELECT * FROM Sales2008
UNION ALL
SELECT * FROM Sales2009
Now let’s run a simple query that returns one row
SELECT * FROM sales WHERE YearCol = 2007 AND orderid = 1
Look at the execution plan
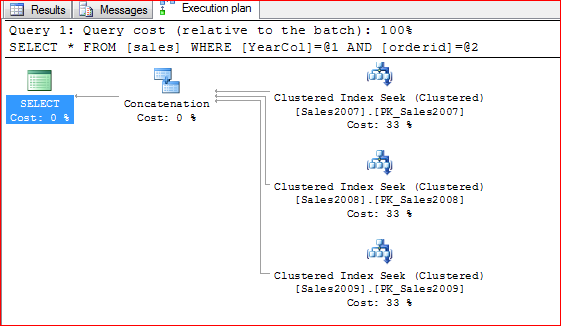
Ouch, it touches all 3 tables.
I want to be able to insert directly into the view, this way I don’t have to worry about which table I have to reference and I also don’t want to mess around with dynamic SQL to accomplish that. Below is a simple insert statement
INSERT INTO Sales
SELECT 2007,0,NEWID()
I get a nasty error
_Msg 4436, Level 16, State 12, Line 1
UNION ALL view ‘tempdb.dbo.Sales’ is not updatable because a partitioning column was not found._
SQL Server does not know into which table you want to insert…this is also the reason the select query from before touched all 3 tables
We can easily fix this by adding a constraint on each table and specifying the valid year. So on Sales2007 yearcol can only be 2007
ALTER TABLE Sales2007 ADD CONSTRAINT ch_2007 CHECK (yearcol = 2007)
ALTER TABLE Sales2008 ADD CONSTRAINT ch_2008 CHECK (yearcol = 2008)
ALTER TABLE Sales2009 ADD CONSTRAINT ch_2009 CHECK (yearcol = 2009)
Now if you try to insert into the view, you will succeed
INSERT INTO Sales
SELECT 2007,-1,NEWID()
Congratulations, you just created your first partitioned view.
How about that same select statement from before? let’s try it again
SELECT * FROM sales WHERE YearCol = 2007 AND orderid = 1
Here is the execution plan
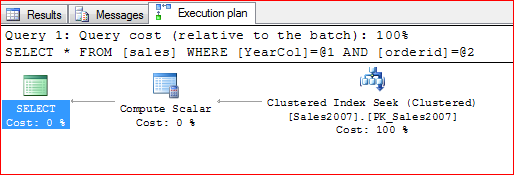
Look at that…because of the constraints that we have added, SQL Server knows it only needs to fetch data from the table with the 2007 data.
BTW you can create partitioned views across servers. These are called federated partitioned views and you would create them by using 4 part notations. Here is a small example
create view Test
as
select * from DB.dbo.Table --local server
union all
select * from Server2.DB.dbo.Table -- linked server
union all
select * from Server3.DB.dbo.Table -- linked server
You would have a variation of the same view on all 3 servers. One bad thing is that if one of the servers is unavailable then the whole view is unavailable.
Partitioning in SQL Server 2005 and up
When you use native partitioning you don’t need to create 3 tables anymore, you just have one table and SQL Server will create as many partitions as you specify. As a matter of fact every table that you create in SQL Server and up is partitioned, by default it will have one partition unless you partition it yourself into multiple partitions.
Let’s mimic what we did before. Instead of three tables we now only need to create one table
CREATE TABLE SalesPartitioned(YearCol SMALLINT NOT NULL,OrderID INT NOT NULL, SomeData UNIQUEIDENTIFIER DEFAULT newsequentialid())
GO
We are going to insert the same data we did as in the SQL Server 2000 version
INSERT SalesPartitioned (YearCol,OrderID)
SELECT 2007,number
FROM master..spt_values
WHERE type = 'P'
UNION ALL
SELECT 2008,number + 2048
FROM master..spt_values
WHERE type = 'P'
UNION ALL
SELECT 2009,number + 4096
FROM master..spt_values
WHERE type = 'P'
We will now add a primary key
ALTER TABLE dbo.SalesPartitioned ADD CONSTRAINT
PK_Sales PRIMARY KEY NONCLUSTERED (YearCol,OrderID)
Now it is time to create our partition function. Here is how we will do it
CREATE PARTITION FUNCTION pfFiscalYear(SMALLINT)
AS RANGE RIGHT FOR VALUES(2007,2008,2009)
What that does is actually create 4 partitions, one for 2007, one for 2008, one for everything after 2008, and one for everything before 2006.
<=2006 = 2007 = 2008 >= 2009
You can verify this by using the function $partition
select 1 AS val,$partition.pfFiscalYear(1) AS partition UNION all
select 2006,$partition.pfFiscalYear(2006) UNION all
select 2007,$partition.pfFiscalYear(2007) UNION all
select 2008,$partition.pfFiscalYear(2008) UNION all
select 2009,$partition.pfFiscalYear(2009) UNION all
select 2010,$partition.pfFiscalYear(2010) UNION all
select 3000,$partition.pfFiscalYear(3000)
And here is the output
val partition ----------- ----------- 1 1 2006 1 2007 2 2008 3 2009 4 2010 4 3000 4
Now that we have the partition function, we need a partition scheme. A partition scheme is used to map boundary values in partition functions to filegroups. You can have one filegroup for each year placed on a different spindle, this way you don’t have to wait for the disk if all partitions are on the same spindle. For the sake of simplicity we only have one filegroup. Here is how to create the partition scheme
CREATE PARTITION SCHEME psFiscalYear
AS PARTITION pfFiscalYear ALL TO ([PRIMARY])
Partition scheme ‘psFiscalYear’ has been created successfully. ‘PRIMARY’ is marked as the next used filegroup in partition scheme ‘psFiscalYear’.
Now we will add a clustered index and partition this on the YearCol column, the syntax looks like this
CREATE CLUSTERED INDEX IX_Sales ON SalesPartitioned(YearCol,OrderID)
ON psFiscalYear(YearCol)
Now, let’s compare the plan for both partitioned views and partitioning in 2005 and up
SELECT * FROM SalesPartitioned WHERE YearCol = 2007 AND orderid = 1
SELECT * FROM Sales WHERE YearCol = 2007 AND orderid = 1
Here is the execution plan
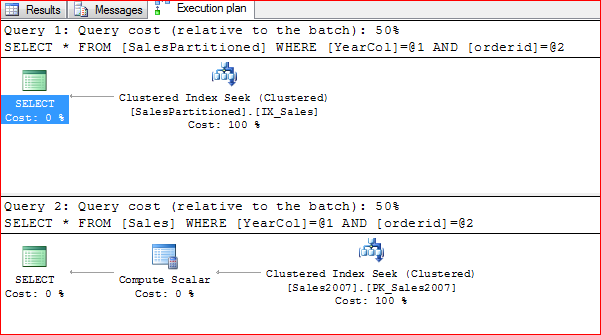
As you can see the cost is the same for both
We can do a simple insert just like before, there is no need to specify any partitions
INSERT INTO SalesPartitioned
SELECT 2007,-1,NEWID()
If you want to see how many rows each partition holds, you can use one of these two mehods
SELECT partition_number,rows
FROM sys.partitions
WHERE object_id = OBJECT_ID('SalesPartitioned')
SELECT YearCol, $PARTITION.pfFiscalYear(YearCol) AS Partition,
COUNT(*) AS [COUNT] FROM SalesPartitioned
GROUP BY $PARTITION.pfFiscalYear(YearCol),YearCol
ORDER BY Partition;
GO
output
partition_number rows ---------------- -------------------- 1 0 2 2049 3 2048 4 2048 YearCol Partition COUNT ------- ----------- ----------- 2007 2 2049 2008 3 2048 2009 4 2048
Find out more
I briefly covered partitioning in this post, there is much more you can do with partitioning. I did not cover merging, deleting partitions, switching tables in and out of partitions.
Below are links to two white papers on partitioning, I highly recommend you read these before implementing partitioning.
Partitioned Tables and Indexes in SQL Server 2005
Table-based partitioning features in SQL Server 2005 provide flexibility and performance to simplify the creation and maintenance of partitioned tables. Trace the progression of capabilities from logically and manually partitioning tables to the latest partitioning features, and find out why, when, and how to design, implement, and maintain partitioned tables using SQL Server 2005. (41 printed pages)
Get it here: http://msdn.microsoft.com/en-US/library/ms345146(v=SQL.90).aspx
Partitioned Table and Index Strategies Using SQL Server 2008
When a database table grows in size to the hundreds of gigabytes or more, it can become more difficult to load new data, remove old data, and maintain indexes. Just the sheer size of the table causes such operations to take much longer. Even the data that must be loaded or removed can be very sizable, making INSERT and DELETE operations on the table impractical. The Microsoft SQL Server 2008 database software provides table partitioning to make such operations more manageable.
Partitioning a large table divides the table and its indexes into smaller partitions, so that maintenance operations can be applied on a partition-by-partition basis, rather than on the entire table. In addition, the SQL Server optimizer can direct properly filtered queries to appropriate partitions rather than the entire table.
This paper covers strategies and best practices for using partitioned tables and indexes in SQL Server 2008. It is intended for database architects, developers, and administrators of both data warehouse and OLTP systems, and the material is presented at an intermediate to advanced level. For an introduction to partitioned tables, see “Partitioned Table and Index Concepts” in SQL Server 2008 Books Online at http://msdn.microsoft.com/en-us/library/ms190787.aspx.
This paper is very long (65 pages) this is why it is offered as a downloadable Microsoft Word document.
Get it here: http://msdn.microsoft.com/en-us/library/dd578580(v=SQL.100).aspx
 Denis has been working with SQL Server since version 6.5. Although he worked as an ASP/JSP/ColdFusion developer before the dot com bust, he has been working exclusively as a database developer/architect since 2002. In addition to English, Denis is also fluent in Croatian and Dutch, but he can curse in many other languages and dialects (just ask the SQL optimizer) He lives in Princeton, NJ with his wife and three kids.
Denis has been working with SQL Server since version 6.5. Although he worked as an ASP/JSP/ColdFusion developer before the dot com bust, he has been working exclusively as a database developer/architect since 2002. In addition to English, Denis is also fluent in Croatian and Dutch, but he can curse in many other languages and dialects (just ask the SQL optimizer) He lives in Princeton, NJ with his wife and three kids.

