


Welcome to the last class of HA / DR week for SQL University. It has been a great week discussing these topics with all of you. We [recapped][1] those classes in order to highlight the key points over the week yesterday. So far we’ve covered a great deal but really have only scratched the surface of SQL Server features for HA and DR. Today will be another scratch in the surface regarding the High Availability points for SQL Server. Be sure to check the resources links through this article. They will greatly add an extension to today and further build your knowledge of the vast amount of abilities we have at our disposal.
Now that HA / DR week is completed, please take a moment to rate this week (and others) by filling out the [SQL University Course Evaluation][2] and select HA/DR Week.
What is HA?
High Availability (HA) for SQL Server can be defined in one sentence: Keep data available 100% of the time. That really is the objective of HA and nothing short of that.
Realistically, 100% is unachievable given the nature of computing. There are needs for a SQL Server and Windows Server to be rebooted at least once a year. This is to allow for updates on both SQL Server and Windows to be maintained. So the ranking method we use for measuring high availability is the “nines” scale. The five nines is a goal that most database
administrators and teams set for their standards. The five nines level is a height of availability that is truly an achievement and one to be proud of.
The table below illustrates the availability calculation. This table has been used for quite some time and has been adopted by IT teams as the measurement for downtime. Downtime equates to uptime (depends on if you are talking to a CTO, CEO or an IT manager how to phrase it).
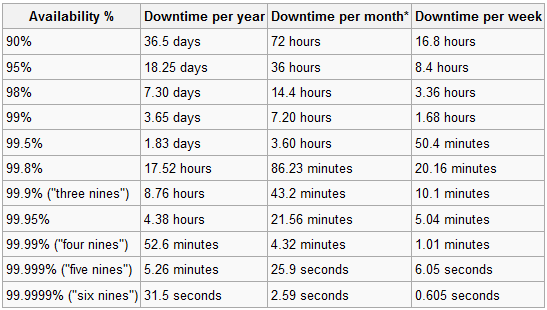
The six nines goal is almost unachievable but can be done in some infrastructures. Why are the six nines almost out of reach? Given that a reboot on Windows takes a little under 2 minutes, reaching only a 31 seconds downtime goal becomes a bit farfetched. Even if clustering and mirroring is setup, the failover times still will add up to around 15 seconds per failover. The five nines is a goal that you can achieve with a mid-level installation and still meet the needs to keep your systems up to date yearly.
Windows clustering has come a long way over the last few versions. Windows Server 2008 in particular has a sound clustering service that is more stable than its predecessors (In this author’s opinion). Windows clustering will give you the ability to automatically failover due to hardware failures and most Operating System failures. The concept of this ability alone allows the setup to be valuable to HA strategies. Clustering consists of two or more physical servers. These physical servers act like a partnership and are always in communication with each other ensuring that their specific roles are being met. These servers can be in a state of Active or Passive but one must be in a Active state at all times.
A benefit to Windows Clustering is the storage location of the actual databases. This would be located on disk (NAS, SAN etc…) outside the physical servers. Given this, we enhance HA by having the ability to replicate the disk along with the safety of the cluster acting in partnership with DR. Mirroring can be added to the cluster fully enhancing the entire landscape of the true HA strategy. Windows Server 2008 Clustering all together is a straight forward setup and deployment but will take added knowledge and research to ensure the cluster is configured to the specifics of each environment. With any cluster, there is complexity in the configurations and ensuring the two servers stay in sync for programs, hardware and services but administrative tasks are much lighter than they were in the past.
Maintenance and downtime
Downtime can be caused by any type of disruption to the availability of data. Maintenance tasks like index rebuilding, updates and ETL loads all fall into that category. When doing large index rebuild tasks, the tables may become unavailable to the users. In the database view of this, they are simply locked at this time. This equates to almost complete loss of the ability to access them though and thus, a failure in our HA strategy. These tasks should be planned out careful to prevent this type of failure in HA.
Windows and SQL Server updates must be maintained. This is not optional. Every update should be analyzed carefully and the full extent of its impact on the systems taken into consideration. Some updates may cause SQL Server services to stop or other supporting services that are needed to maintain availability. If they are, the downtime should be planned carefully to prevent the HA landscape from doing its job of preventing loss and availability. That means pausing mirroring or failing over nodes in a cluster to retain the availability of data services as much as possible.
Geo-Clustering
Geo-Clustering allows us to plan High Availability across geographically located sites. This is achieved through replication of disk to each site and essentially mirrors each system to the next. This HA option of high availability as a hefty price tag on hardware and networking abilities. Recently, Paul Randal ([Blog][3] | [Twitter][4])published a White paper [Proven SQL Server Architectures for High Availability and Disaster Recovery][5]. This went over HA setups (and DR) that are in use in businesses now and proven to work effectively. This white paper goes into detail on actual in-place configurations in Geo-Clustering as well. This class lucks out on the timing of this publication by us being able to link to it as a resource in understanding large business HA and Geo-Clustering.
Database Mirroring
Database mirroring was introduced in SQL Server 2005 Standard and Enterprise editions. Prior to the introduction of database mirroring, there was difficulty in achieving HA with SQL Server. Clustering and disk replication were options but still limited. With database mirroring the options for HA landscapes opens up greatly. This doubled with the advancements in Windows Clustering added a great deal of enterprise abilities to SQL Server.
Our landscape for data services can take on a new form for HA and exist without Windows Clustering as well.
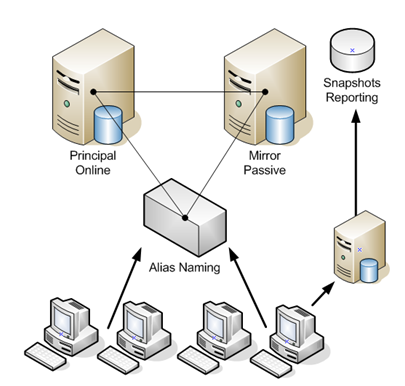
What this type of HA landscape provides is even more stripped down overhead in administrative burdens and we have cost savings opportunities to assist in providing a HA solution.
In the diagram above, the landscape consists of two physical database servers. Those database servers a standalone installations and active as each unique entity to the infrastructure. Alias naming can be added to the scenario to ensure the clients access the database servers in the event of a failover. Alias naming can be forgone with the changes in recent years to the ability of connections from applications to allow for a failover specification.
Data Source=myServerAddress;Failover Partner=myMirrorServerAddress;Initial Catalog=myDataBase;Integrated Security=True;
```<p align="center">
<i>Resource: <a href="http://www.connectionstrings.com/sql-server-2008">ConnectionStrings.com</a></i>
</p>
We can see in the example connection string above the Failover parameter which allows us to make applications much smarter as opposed to recent years with actually developing tests in code to determine the availability of data services.
Another addition is added to the diagram that is provided with Enterprise Edition. That is snapshots capabilities. In this landscape (and clustering) a path can exist from another reporting server to snapshots that are taken of the mirror. This reporting solution is a huge benefit to the entire structure of the data services by lower the activity on the OLTP side. Reporting activity has always been an historical hardship of database administrators and keeping services for both reports and operations from preventing each other's ability to serve the business.
## **Working with database mirroring**
To go deeper into database mirroring, we will work from a recent setup located at, [Mirroring Hands On with Developer Edition][6]. In this setup, Developer edition is used to provide all of the possible configurations provided in mirroring. The setup and purchase of Developer Edition is highly recommended to become familiar with these features.
The primary features we lose when moving to Standard Edition are Asynchronous
Mirroring and Snapshot capabilities of the Mirror. One important factor of snapshot abilities is, the snapshot cannot occur while the mirroring is in a synchronizing state or applying transactions. In an asynchronous setup (High performance), depending on the number of transactions, this state can be harder to schedule for snapshot creations. These two features are a large part of mirroring and the flexibility in configuring it. Weigh in the needs of mirroring greatly and the loss of these features when not putting the budget in for Enterprise Edition.
After going through the developer setup in the link above, we can start to look at options in mirroring and things to watch for.
## **Operating Modes**
Database Mirroring allows for three operating modes.
* High Availability
* High protection
* High performance
In order to achieve HA with out of the box SQL Server, we enlist in the High Availability operating mode. This setup runs in a synchronous set of operations that apply transactions to the logs on both the mirror and principal prior to returning success commits back to the applications. The mirroring landscape consists of three physical servers, the principal, the mirror and the witness.
> <span class="MT_red">Note: The witness can be any edition of SQL Server but the principal and mirror must be the same edition. The principal can be a previous version than the mirror but this is only recommended in upgrade methods. The witness can be located on the mirror but this is not recommended due to the chance of losing the mirror and thus, losing the witness.</span>
The remaining two operating modes take the witness and automatic failover out of the landscape. This is not optimal in achieving HA. Without automation and the active ping in mirroring, the downtime is greater and human interaction is required.
## **What can go wrong?**
The worst thing that can happen in database mirroring is losing the network behind it. This can cause a complete loss of data services.
Another known problem is referred to as Split-brain. In this situation, both the Principal and Mirror have taken on the role of a principal. In the landscape in which alias's are utilized this can be a severe problem to accessing the databases.
Corruption (page errors) that occurs on the Principal will follow to the mirror. Database mirroring does enlist in _automatic page-repair_. This is now available in SQL Server 2008 and SQL Server 2008 R2. The automated page-repair will attempt to repair any page errors that are sent to the mirror by requesting the transactions (or fresh copy of the pages) again from the principal. This repair will work in some scenarios but if the corruption is too great and requires any type of loss in data, an error will persist.
When a mirror does receive errors (even if capable of fixing), the mirror goes into a suspended state. This suspended state will persist until the error is resolved. If the error cannot be resolved by automation of the mirroring abilities, the mirror will stay in the suspended state. This usually will cause a clean setup of the mirroring landscape. In a worst case scenario, the errors that came from the principal are great enough that repairing the principal is the priority.
Transaction log growth must be maintained in mirroring. Database mirroring requires the databases to be in Full recovery. This means that the transaction logs must be maintained and sized properly. If they are not, the logs will grow and at some point the need to shrink them will undoubtedly occur. These operations are not allowed in a mirror though and the mirror will need to be broken to do them. It is highly recommended to take all the necessary steps to maintain a full recovery state. Keep this in mind while performing index maintenance especially.
## **Final Thoughts**
The combination of Windows Clustering and Database Mirroring will allow for the objective of data services to meet High Availability goals. With Database Mirroring, we can achieve HA with the operating mode of High Availability while not needing a clustered environment (although recommended). This landscape lowers cost and allows for flexibility in some applications that may have particular needs outside of the clustering scope.
Achieving High Availability should be seamless to the user community. Failover situations must be automated in order to retain HA and limited to no exposure to the users at the time a failover is needed. Working with the applications and vendors to achieve these goals is sometimes required but often fully achievable.
This concludes the SQL University DR/HA Week. I hope you enjoyed talking about the topics and look forward to hearing all of your feedback on taking what we've discussed while planning your own data securing strategies with HA and DR. As with all of the SQL University weeks, your feedback is greatly appreciated so we know how we are doing. When you have a moment please take a moment to fill out the [SQL University Course Evaluation][2] and select HA/DR Week.
Thank you for attending once again and thanks to Jorge Segarra ([Blog][7] | [Twitter][8]) for allowing me the pleasure of discussing all of these topics with you.
[1]: /index.php/DataMgmt/DBAdmin/sqlu-taking-a-break-for-recess
[2]: https://spreadsheets.google.com/a/sqlchicken.com/viewform?hl=en&formkey=dDBoSW02QldrTTc2dER3WVZheUlEX3c6MQ#gid=0
[3]: http://sqlskills.com/blogs/paul/
[4]: http://twitter.com/paulrandal
[5]: http://blogs.msdn.com/b/tommills/archive/2010/06/02/new-sql-server-2008-r2-high-availability-whitepaper-published.aspx
[6]: /index.php/DataMgmt/DBAdmin/sql-server-2008-mirroring-setup
[7]: http://sqlchicken.com/
[8]: http://twitter.com/sqlchicken


