


Several years ago, I launched SQLisHard to help folks learn SQL. Some folks learn well from books or videos, but others learn best by getting in there and running queries. I monitored and tweaked things for about a year, trying to get the first set of exercises smoothed out. Then, like many folks, I was sidetracked by other projects and work responsibilities.
For about $10/month, this little site has kept running and helping folks. I expected to see traffic die off, since I wasn't adding more content. Instead, there's been nearly 7000 folks that have stopped by and successfully completed one or more exercises despite a total lack of marketing.
The hosting is oversized for what it is, most of the technology is not what I would pick today for options, but it just keeps ticking. So I'm dusting off the build pipeline, rebuilding some data analytics so I can see what's going on, and started fashioning a new set of exercises.
Here's how I went about reviving the application.
Delivering Change: The Build Pipeline
One of the things that made it easy to tinker with SQLisHard is the build pipeline for delivering updates. Most of the scripts live in the repo, but I hadn't bothered to document it. Luckily, I had an old backup of the original build server VM and was able to recreate the build process on a much newer one.
Why did I bother?
A build pipeline makes delivering changes consistent. This application has 2 separate databases, runs user-entered queries against a real database, and has to provide accurate feedback every time (or risk hurting someone's progression). A pipeline provides both safety and speed. I was experimenting with several different things at the time, so I have rudimentary testing covering all types of situations. By the time the changes roll out to the website and apply changes to 2 separate SQL Server instances, that one button push has run:
- Clean nuget + npm installation to ensure consistency
- MS Build to make sure they work
- Some unit tests to make sure the code is happy
- Applied SQL changes to two beta databases to verify updates work and complete quickly
- Asset minification for faster site loading
- Deployed the site to a beta web server
- Run 13 quick UI tests via Chrome Headless to make sure everything plays together
It was a little painful to bring back to life, but infinitely safer then applying changes manually. It's past time for every company to run a pipeline, and I'm more than happy to dive into more details or other build services if folks are interested.
Visibility into usage
The 2013 version of SQL is Hard tracked statistics on how many folks were successful or unsuccessful at each step along the way.
On the SQLisHard front, it looks like exercises 1.0, 1.2 and 4.0 need refinement, they have the highest error rates pic.twitter.com/Hv5OfOL10L
— Eli Weinstock-Herman (@Tarwn) June 14, 2013
Visibility into the flow from step to step helped me make adjustments and help folks make it all the way through the exercises. This site used a bunch of experimental things, so the data originally lived in a beta Splunk Cloud offering that was discontinued years ago (and replaced by a cloud offering that did not have an API...). Unfortunately, this activity is not tracked well in the database either.
Azure Insights has come a long way, so I decided to switch to that and not get distracted by rewriting the database back-end. With a few lines of JavaScript, I now have live events flowing into pretty charts again:
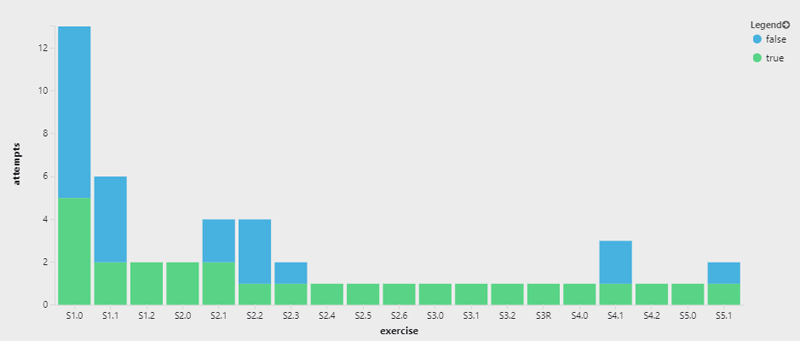
SQL is Hard: Azure Insights
Every query someone tries in SQLisHard is executed against a sample database and returned to the front-end. Once the front-end receives the result, I send an event to Insights to report the Exercise Id and Status:
dataService.exercises.executeQuery(currentQuery.toStatementDTO(limitResults), function (data) {
// ... receive query results, extract completion status, and display ...
trackEvent('executeQuery', {
exerciseSet: exercises().id,
exercise: exercises().currentExercise().id,
completedSuccessfully: exerciseCompleted
});
});
I query the data in Application Insights (https://azure.microsoft.com/en-us/services/application-insights/) to count the number of success/non-success calls have occurred for each exercise:
customEvents
| where timestamp > now(-7d)
| project exercise = tostring(customDimensions.exercise), success = tostring(customDimensions.completedSuccessfully)
| where notempty(exercise)
| summarize attempts=count() by exercise, success
| order by exercise asc, success desc
| render columnchart
Where this pays off is when I start making new exercises public. Now I'll have immediate visibility into how folks are progressing and I can try to improve the exercise descriptions to help as many folks get through as I can.
New Exercises Coming Soon: Aggregation
The first exercise set focused on some basic building block SELECT statements. We went through some beginning SELECT * statements, listed columns, and column aliases. We performed WHERE statements with equivalence, LIKE, and BETWEEN. Then we added in JOINs with ON statements.
One of the great things about a relational database is the ability to mine across those related datasets for new information. Aggregation plays a big part here, so I've started building an exercise set that looks like this:
- COUNT
- SUM
- GROUP BY one field
- GROUP BY multiple fields
- MIN/MAX
- AVG/STDEV
- HAVING
- ORDER BY
- Aggregation data from INNER JOIN
- LEFT JOIN
- Then possibly some tricks, like SUM(IF/ELSE/END) statements
If this works out, I'll have a test link posted on twitter (@sqlishard) and, after a trial period, will roll it out live.
I can't promise this will usher in a great deal of additions, it's hard to jump in this code base and not immediately start rewriting all the things plus I have a half-dozen other projects I'd like to be working on too. We'll see what happens.
 My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.
My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.

