


With almost all databases running on SQL Server, at some point there will be a need to load data, move data or delete data from tables that are not ideally setup for the operations in large batch sizes. While many methods exist to handle the actual task of any of these needs, a commonly overlooked side effect of performing large batch operations is, transaction log growth.
For over a decade now, one of the most commonly answered questions on the community forums and all around is, “My transaction log grew out of control and I need to reclaim my disk space. How do I prevent this?”
First, this falls under the concept that most have that SQL Server has a memory leak. No, there isn’t a memory leak in SQL Server. It is all your fault why SQL Server processes consume all the memory on a server due to not configuring the instances accurately. With transaction log management, this is the same concept. While in full recovery model, transactions are required to be logged in order to be in a recoverable state based on the concepts of a full recovery model. This means that a large batch operation that is not in true bulk load modes, will be logged at a higher rate than normal operations. With this being known, the transaction log requires attention and management during the process of the tasks that are loading a higher rate of data into or out of a database.
Before looking at a method for doing this, there are several key questions that need to be answered before considering what and how a transaction log will be maintained during the processing.
- Is log shipping being used
- Have I managed my VLFs
- Is mirroring or availability groups in place
- Can my transaction log backups destination disk space handle the added needs
- Can I process during a minimal user active time period
These are just a few to look at. The primary, and most important to think about, is log shipping involved. This is a critical question due to the way log shipping is typically utilized as a Disaster and Recovery method. In this method, log backups are sent to an offsite location for retention and recovery purposes based on the loss of the primary source. Without this setup, there could be a massive amount of loss in data due to a disastrous event. For this reason, the use of waiting between processing may be needed while transaction log backups are copied offsite.
Archiving
To perform an archive, the actions will be to grab rows based on an identifier, insert them to the archive location, and delete them from the source. The flow of this is shown below.
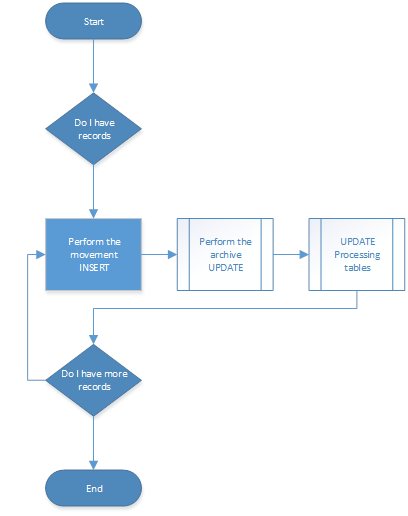
Again, the main objective to discuss is to manage the transaction log during this process. To do that, options such as moving to SIMPLE recovery model or forcing transaction log backups to occur more often can be done to manage the transaction log usage. For this, if log shipping is used, simply manipulating the schedule can be performed. For example, if the backup occurs every 15 minutes, moving to every 5 minutes can be effective. Once the process is performed and completed, move back to 15 minutes.
Knowing this and already knowing a base utilization of the transaction log, we need to perform a test of the process to monitor the transaction log growth that will occur. Ideally, we want to maintain the transaction log to around 25% space used for this batch processing event. This allows plenty of room to the other logging events occurring and if based on a free space management of the log at 25% free, we should be maintaining a no-growth solution during processing.
To monitor the log growth, the SQL Agent can be utilized along with reading the DMV sys.dm_os_performance_counters.
SELECT db.[name] AS [Database Name]
,ls.cntr_value AS [Log Size (KB)]
,lu.cntr_value AS [Log Used (KB)]
,CAST(CAST(lu.cntr_value AS FLOAT) / CAST(ls.cntr_value AS FLOAT) AS DECIMAL(18, 2)) * 100 AS [Log Used %]
,getdate()
FROM sys.databases AS db
INNER JOIN sys.dm_os_performance_counters AS lu ON db.NAME = lu.instance_name
INNER JOIN sys.dm_os_performance_counters AS ls ON db.NAME = ls.instance_name
WHERE lu.counter_name LIKE N'Log File(s) Used Size (KB)%'
AND ls.counter_name LIKE N'Log File(s) Size (KB)%'
AND ls.cntr_value > 0
AND db.database_id = 41
OPTION (RECOMPILE);
Original query utilized from Glenn Berry’s diagnostic queries and altered for the needs of this task
This query will provide the database, log size, log used in KB and then the log used as a percentage. To fully baseline the process, utilizing a SQL Agent Job to run every 10 seconds is optimal. Once the process to archive is completed, the data will allow for a determination of when and how often a transaction log backup will need to occur to maintain the transaction log and prevent unwanted growth.
To complete the actual job steps, prepare by creating a table in a database outside the one that is being loaded by utilizing the SELECT INTO statement.
SELECT db.[name] AS [Database Name]
,ls.cntr_value AS [Log Size (KB)]
,lu.cntr_value AS [Log Used (KB)]
,CAST(CAST(lu.cntr_value AS FLOAT) / CAST(ls.cntr_value AS FLOAT) AS DECIMAL(18, 2)) * 100 AS [Log Used %]
,getdate()
INTO [WATCH]
FROM sys.databases AS db
INNER JOIN sys.dm_os_performance_counters AS lu ON db.NAME = lu.instance_name
INNER JOIN sys.dm_os_performance_counters AS ls ON db.NAME = ls.instance_name
WHERE lu.counter_name LIKE N'Log File(s) Used Size (KB)%'
AND ls.counter_name LIKE N'Log File(s) Size (KB)%'
AND ls.cntr_value > 0
AND db.database_id = 41
OPTION (RECOMPILE);
Then for the actual job step, simply perform an INSERT on each execution
INSERT INTO [WATCH]
SELECT db.[name] AS [Database Name]
,ls.cntr_value AS [Log Size (KB)]
,lu.cntr_value AS [Log Used (KB)]
,CAST(CAST(lu.cntr_value AS FLOAT) / CAST(ls.cntr_value AS FLOAT) AS DECIMAL(18, 2)) * 100 AS [Log Used %]
,getdate()
FROM sys.databases AS db
INNER JOIN sys.dm_os_performance_counters AS lu ON db.NAME = lu.instance_name
INNER JOIN sys.dm_os_performance_counters AS ls ON db.NAME = ls.instance_name
WHERE lu.counter_name LIKE N'Log File(s) Used Size (KB)%'
AND ls.counter_name LIKE N'Log File(s) Size (KB)%'
AND ls.cntr_value > 0
AND db.database_id = 41
OPTION (RECOMPILE);
Once the batch load is performed, analyze the data in the Watch table
SELECT [database name]
,[log size (KB)]
,[log used (KB)]
,[log used %]
FROM [Watch]

With this, we can see that the setup that was put in place to back the log up every minute, succeeded in the goals of maintaining the transaction log utilization and prevented the unwanted growth.
The information above has all been based on a 10 million row table that is archived, or data moved, to another table. The identifier was a combination of a transaction date and identity seed column as the row identifier. To allow this to move into a batch processing method, insert the rows that are to be archived into a table that holds the identity column. This is used while processing to manage while rows have to be moved. While each batch, 10,000 or another number designated as a good batch size, set a column to in process and then when completed, processed. A transaction log was set at 1GB and then monitored for normal usage of around 2%.
CREATE TABLE [dbo].[ArchiveTemp](
[ROWID] [int] IDENTITY(1,1) NOT NULL,
[ID] [int] NULL,
[TABLENAME] [nvarchar](255) NULL,
[PROCESSED] [tinyint] NULL,
[PROCESSDATE] [datetime] NULL
) ON [PRIMARY]
Above is what this type of processing table would appear as. With this, the initial load for any data older than the most recent 2 years, appears as follows.
INSERT INTO ArchiveTemp (ID,TABLENAME)
SELECT ID,'MyTable' FROM 'MyTable' WHERE TRANSACTIONDATE <= (SELECT DATEADD(Year,-2,MAX(TRANSACTIONDATE)) FROM TRANFILE)
AND ID NOT IN (SELECT ID FROM ArchiveTemp WHERE TABLENAME = 'MyTable')
With this method, it is important to note that there will be 1 primary logged event and 4 logged events per batch. This is due to the initial pull of the IDs into the processing table and then for each batch, an event to update the rows to in process, an event to insert the rows into the archive table, an event to update the rows to processed, and then, an event to delete the rows form the primary table.
This adds transaction log events but all can be managed while monitoring the transaction log growth effectively, as described earlier. This method id stable for a few reasons. It allows for the batch processing to occur and possibly even run log backups in the process itself to maintain the transaction log utilization, and it also allows for a point of recovery in the process for a restart scenario. If the task is halted for any reason, the rows would have been moved and are either in process or the load is half completed. Having the identifier of the in process vs. processed rows is essentially to a quick, stable and reasonably non-complex method of knowing where to restart.


