


A computed column can be described as an expression that is evaluated in a table in the form of a column value. The computed column can have either a physical or logical representation. This means, if a computed column is created or altered to apply the persisted attribute, the actual computed value from the expression will be stored in the table physically. If the persisted attribute is not set, the column is evaluated upon request, and is logical. It is important to note that when persisted is utilized, a computed column is evaluated at any time the columns that are part of the expression being used are updated in any way.
Cardinality is an interesting topic when computed columns are used. In many cases, tuning steps are taken by using computed columns when arithmetic operations are used in queries such as
SELECT Col1 FROM tbl WHERE Col2 + Col3 = 1
The above query can be tuned in many cases by altering the table to add a computed column that already performs the expression Col2 + Col3. Once this is done, statistics can be or are, created on the columns and the estimation of 30% selectivity is not performed. SQL Server 2005 and on uses an estimated 30% selectivity sample or estimation in the case of the query shown above in order to generate the plan. This can be a performance bottleneck in large tables.
Once the computed column is created and persisted, the query could be altered to look like the following
SELECT Col1 FROM tbl WHERE ColComputed = 1
Indexing on ColComputed is typically performed at this point to fulfill the objective of an optimal execution plan.
Taking a deeper look
As we’ve discussed, using computed columns can be a good tuning method in some cases. Computed columns and cardinality or estimation of rows is also directly affected by how the computed column is created.
To look at the cardinality a little closer, take the following query that was written to read the Credit database from SQLSkills.
select corp_name + ' ' + city from corporation where
corp_name + ' ' + city = 'Corp. Boston Key StonesInc. '
A query written this way is not as uncommon as you may think. I’ve seen many instances in both client and mobile applications where string values like the above ‘Corp. Boston Key StonesInc.’, are sent to the database engine to prevent multiple calls and trim the packet that is needed to be sent. This type of query requires some work on the tuner’s part to find an optimal plan.
Looking at the plan as it is written above, we can see there is areas that can be improved. One of those areas is the estimation versus the actual rows that are generated.
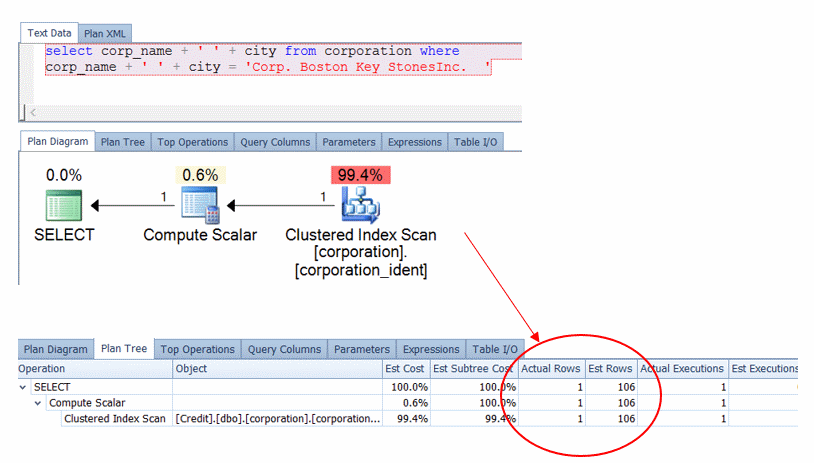
In a lot of cases, the major difference between estimated and actual rows can mean outdated or stale statistics. However, in this particular case, the statistics were created at the time this query was executed, given the auto create statistics setting on the database. The root cause of this difference in estimated versus actual rows is due to the use of corp_name + ’ ’ + city. There are 500 rows in the corporation table so the 106 estimated rows is generated from the estimated 30% selectivity that is performed.
We can look at this in another table with more rows, member.
select member_no from member where lastname + ',' + firstname = 'INFANTE,WLTANAWOIKGLQR'
The member table has 10,000 rows and the estimated rows generated from the above query are 1000. As we’ve seen, the 30% is an estimated number that can be thought of as, up to 30% on a high range. In this case, only 10% was generated.
Computed Column
Fixing the above plan when performance problems are seen from the query being executed several times can be done by utilizing computed columns. This method is the same concept that was mentioned earlier when a calculation is performed on two or more columns in order to retrieve data matching the expressions final value. There is really one gotcha that should be taken into account when creating a computed column: whether it should be persisted or not. Let’s look at a non-persisted computed column first.
Alter the corporation table to add a computed column on the expression corp_name + ’ ’ + city.
ALTER TABLE corporation
ADD [corp_city_computed] AS (([corp_name]+' ')+[city])
Execute the query below and review the results in Plan Explorer.
select corp_name + ' ' + city from corporation where
[corp_city_computed] = 'Corp. Boston Key StonesInc. '

We’ve actually introduced more problems with the computed problem as seen above. Now the compute scalar operations are required, and notice the estimated versus actual rows are now showing 500. 500 is the total number of rows in the corporation table. The reason for this is the failure to use persisted on the computed column. Recall, without a persisted computed column, the expression is evaluated every time the systems needs to read the data. So, in order to fulfill the query, the entire nonclustered index is scanned and the computed column is evaluated. Although we’ve corrected the fact that the estimated and actual rows (cardinality) are now the same, we’ve introduced something that can be, in some cases, even more of a performance problem.
Add Persisted
In order to fully take advantage of the objective of using computed columns to enhance the performance of the query, the persisted attribute needs to be set. To do this, run the following ALTER statement on corporation.
ALTER TABLE corporation
DROP COLUMN [corp_city_computed]
GO
ALTER TABLE corporation
ADD [corp_city_computed] AS (([corp_name]+' ')+[city]) PERSISTED
GO
The ALTER statements above will drop the computed column and add it back on the corporation table while using the persisted setting. This will force the data to be evaluated and stored in the table. Be careful at this point. Creating a computed column with persisted on a large table will take time. The ALTER statement will execute for a variable amount of time based on the expression and the rows that must be evaluated at the time the ALTER statement is performed. During this time, locks will be taken on the table and blocking will, more than likely, occur.
Executing the same query to select on the corporation table results in the following plan.
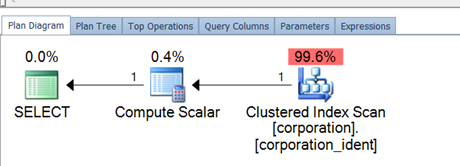
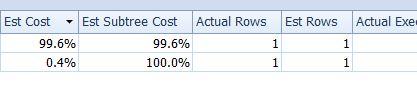
Given the computed column and persisted nature, the estimated versus actual rows now show a value of 1 for each.
Summary
Utilizing computed columns can be extremely effective for tuning certain queries to resolve cardinality issues. While this can be effective, having the persisted setting on or off is vital to the overall effectiveness of the computed column. When creating computed columns, persisted or not, take care in the time it may take to ALTER the table based on the number of rows, data types utilized for the columns in the expression for the computed column and overall, time that may be used with high level locks that can cause severe blocking.
To read more on the selectivity estimate, “Statistics on Computed Columns” by Benjamin Nevarez.


