



Merge Replication is a powerful beastly thing that can bring great joy and great sorrow all in the same 15 minute time span. There is no doubt that Merge Replication is an Enterprise feature. It has grown over the years from the days when all it took was a swift kick to the side of a server rack to knock an agent into starting, to a fancy event handler that shows us the bulk operations as they fly by our network and into the subscribers. Face it: SQL Server 2000 and the word Replication simply were a scary combination for some administrators.
SQL Server has grown from a small slice of overcooked microwave bacon into a full order of thick sliced mouthwatering heaven. This growth has placed it amongst the leaders in the Database Server world, a place that was well earned, and we are all reaping the rewards of its success. While this was all going down, Merge Replication formed a stance and started working very well. Limitations were and are still there but fewer than years past.
Today we’re going to talk about a limitation that in all respect isn’t a limitation but more a default behavior in SQL Server. Then we’ll show how to work around it (or with it). We want to get to the thick sliced bacon by the end.
Bulk Loading Data
By default, BULK INSERT and BCP operations disable triggers on the tables they are loading. This is important to know because Merge Replication functions based on triggers. If a table is in a publication and there are background integration jobs using something like SSIS, the default method that is used for some SSIS destination objects is BULK INSERT. This is seen in a Data Flow Task with the AccessMode setting. In order to change this, the property is set to OpenRowset or a few other not-so-default methods.
Role Playing
DBA Fred is in charge of loading sales into the CHEESE_WAREHOUSE_DB. The CHEESE_WAREHOUSE_DB is setup with Merge Replication so a secondary facility has the same data readily available without the network latency between the two sites. Fred has a requirement to load legacy data into the cheese database so reporting can be done from a few applications. Fred uses SSIS because he can bring the data in, transform it and load it quickly.
DBA Joe is in charge of Merge Replication for the entire company. Joe gets a call that there are 361,970 rows of data missing from the offsite location but when the users connect to the home office, the data is there. Users are a little angry because Citrix is used and calling UPS to get the data shipped is quicker that pulling the reports using Citrix.
Fred loaded the data into the home office database using SSIS with an OLE DB Destination set to use TABLOCK and OpenRowset with FastLoad. By all means, Fred should have used SSIS because this loaded the data in under 8 seconds. His manager even gave him a bonus because the load was done so quickly. Fred shouldn’t spend it just yet.
Joe isn’t happy. Replication Monitor shows no errors and the data simply is not there without any explanations at all. TableDiff shows the difference as well as queries he runs. Why does Joe not see the data on the subscriber?
The triggers that should have fired to load the merge tracking tables did not due to the bulk insert operations done by Fred’s package. (no pun intended)
Walk Through
Two databases were created named PUB and SUB. PUB is on a unique instance and SUB is on another unique instance. Merge Replication is setup on one table named PUB_INVENTORY in PUB with a publication named Publication_Inventory. SUB is setup as a subscriber to Publication_Inventory.
PUB.dbo. PUB_INVENTORY has 1,145,743 rows in it. The subscriber on SUB is initialized from a new snapshot to bring it in sync with PUB.
To validate the counts of both tables after Merge Replication and the data is synchronized, the COUNT(*) for each is checked.
1145743 result from SELECT COUNT(*) FROM PUB.dbo.PUB_INVENTORY
1145743 rows result from SELECT COUNT(*) FROM SUB.dbo.PUB_INVENTORY
Another staging table is created that holds 361,970 rows that need to be imported into PUB.dbo.PUB_INVENTORY and then all subscribers are required to get this data.
To load the legacy data, SSIS is used and consists of one Data Flow Task with a direct OLE DB Source to OLE DB Destination. The package is executed with the OLE DB Destination option set for AccessMode to OpenRowset Using Fastload and no other properties altered. The load runs successfully and inserts the 361,970 rows into PUB.
To move the newly inserted data into SUB.dbo.PUB_INVENTORY, the synchronization agent is started.

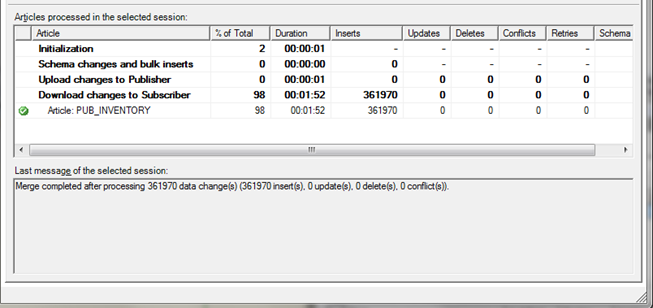
From the above status after completing the agent execution, no data was moved. To validate, another count is performed on SUB.dbo.PUB_INVENTORY with 1,145,743 rows returned. This is still the initial row count that was returned prior to the execution of the SSIS package.
Further validation of PUB.dbo.PUB_INVENTORY shows the count did increase to 1,507,713 rows.
The reason this happened was due to the triggers for Merge Replication not firing during the BULK INSERT that SSIS performs with the FastLoad option. To fix this situation, the SSIS package’s AccessMode can be set to OpenRowset and perform normal insert logging operations. This causes the performance of the total data load to be reduced from 8 seconds to over 14 minutes. The option is almost unusable for Fred. Alternatively, the FastLoadOptions can be used to force the firing of the triggers during the BULK INSERT.
Set the destination options to add the FIRE_TRIGGERS option. The total value and combined options for the FastLoadOptions is as follows.
TABLOCK,CHECK_CONSTRAINTS,ROWS_PER_BATCH = 15000, FIRE_TRIGGERS
Executing the package to load the PUB.dbo.PUB_INVENTORY table shows much better performance. Performance is still slower than the prior execution times without the FIRE_TRIGGERS, but it vastly faster that the OpenRowset setting. Fred is getting happy again.
To validate the Merge Replication operations were set correctly this time, start synchronizing. Open replication monitor to show the details of the changes to the subscriber. Once the synchronization agent is started, the monitor shows the following inserts have completed on the subscriber.
Performance
To put numbers to the loading operations and performance between both with FIRE_TRIGGERS set on and with it set off, BIDS Helper was used with the performance analyzer.
Performance with fire triggers

Performance without fire triggers

As the results show, performance without the triggers is extremely beneficial. However, when replication is being utilized for the tables being loaded, the triggers must be enabled in order to bring the data down to the subscribers correctly.
Work Around
Alternatively, the sp_addtablecontents procedure can be used after a true BULK INSERT operation is performed on the publication table. This procedure will determine if any rows exist in the table and if a row is not found in the merge tracking tables, it is inserted into the tracking tables.
To use sp_addtablecontents in the scenario above; call the procedure after the SSIS package is executed with FIRE_TRIGGERS not set and FastLoad on. Once the package is executed, run the following in the PUB database.
(To show the performance of this method, 1.9 Million rows were inserted into the table on this SSIS execution)
Exec sp_addtabletocontents @table_name = ‘PUB_INVENTORY’
Leaving the filter parameter out will force the entire table to be scanned for rows missing from the tracking tables. The total time to execute this procedure after the 1.9 million row bulk insert took 4 minutes and 20 seconds. After setting the tracking table to synchronize the data correctly, the synchronization agent must be run to perform the inserts on the subscriber. This process took another 12 minutes and 34 seconds. So the payoff in the bulk loading operations were offset by the time it took to insert into the tracking tables and then send the next bulk load operations to the subscriber.
There is a distinct choice that must be made based on when and how data is loaded into tables that are also part of Merge Replication. Using bulk loading operations is still a valid process. Once the table at the publisher is loaded completely, the time of running a procedure like the sp_addtablecontents must be added into the total process. The same bulk load can be done in idividual tasks on the publisher and subscriber as another method. This would completely ignore the merge replication scenario all together. This however is a difficult process at times. Trying to retain the dynamic values or unique values such as primary keys can be tricky and unstable. Planning is everything in how long you can take to load data and exactly how that data is loaded. Hardware makes a large difference in these times but the difference between them is a just comparison.
Happy Bulk Loading!
Resources
Bulk loading table in a Merge Publication: http://msdn.microsoft.com/en-us/library/ms146882.aspx
sp_addtablecontents: http://msdn.microsoft.com/en-us/library/ms176084.aspx
OLE DB Destination: http://msdn.microsoft.com/en-us/library/ms141237.aspx
SQL Server Destination: http://msdn.microsoft.com/en-us/library/ms141095.aspx


