


Undeniably, the largest impact a database administrator can have on a database server’s performance is with indexing. One index can mean the difference between a 30 minute overall time of execution or a few seconds overall time of execution. At the same time, indexing can have a negative impact on overall database server performance. This negative impact can be from too many indexes, overlapping indexes, or indexes that are not defined correctly.
Jason Strate (Blog | Twitter) has written an index analysis script that can assist in showing statistics for all types of index-related topics including missing indexes, foreign key indexing, alignment of indexes, and overall performance of an index. To further the value of this script Jason has developed, we can automate the use of the script by utilizing SQL Server Integration Services to execute the script and export the results to a file that can be later analyzed. This gives us analysis over time, proactive analysis on a database that may change often for query needs and retention of performance impacts from that analysis for later review.
Designing an SSIS Package
The design of the SSIS package that will use Jason’s script involves utilizing dynamic features and methods. This dynamic nature of the package will allow for the script to be executed on several SQL Server Instances and several databases that are located on each of those instances.
The Design
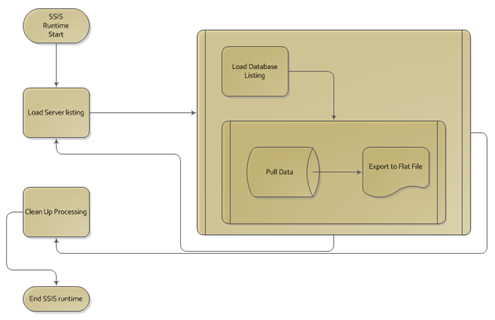
The SSIS package will first use an external file that will have a list of all the servers to collect the index statistics from. In the first process, the file will be read and a data table used to populate the list into a variable of an object data type. This method is commonly referred to in SSIS as Shredding Variables.
Once the variable is loaded with the list of servers from the file in a table format, a Foreach Loop Container is utilized to perform the actual shredding task. For each row in the table contained in the variable, the internal processing will occur.
The internal processing of the Foreach Loop will consist of an Execute T-SQL Task to execute Jason’s script based on the instance the Foreach Loop is focused on (or indexed currently), which will pass the results to another Foreach Loop Container that will process each row returned and insert the row into a flat file destination.
The SSIS Control Flow
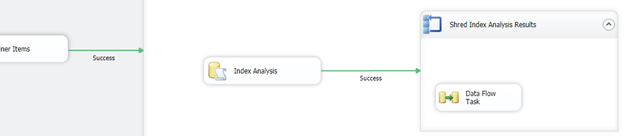
With this design and method used, there are a few bottlenecks that appear. Later we will look at these bottlenecks and put another design together that will allow a higher scalable SSIS package and a direct data flow. The design above has many methods that are valuable and will be shown.
Shredding Variables
With SSIS, configurations can be used to allow a package to become more dynamic with the SQL Server Instance it uses and databases in those instances it connects directly to. In some cases, multiple instances are needed in a situation where the package should iterate through each instance and perform the same task on each instance. To do this, flat files are often a stable and easy solution for other database administrators to implement and alter.
The flat file connection used in this package connects to a text file containing a list of SQL Server Instances formatted as follows.
ONPNTRC0
ONPNTRC0_Mirror
ONPNT
In order to utilize this file and the list, the first task in the package is a script task. This script task opens the file, reads the contents and populates a data table with them. This data table is then set to a variable that is an object type. The code in the demonstration to do this is shown below.
try
{
string Serverlisting;
DataTable dt = new DataTable();
dt.Columns.Add("Server");
Serverlisting = (Dts.Connections["ServerList"].AcquireConnection(Dts.Transaction) as String);
using (System.IO.StreamReader sr = new System.IO.StreamReader(Serverlisting))
{
string line;
while ((line = sr.ReadLine()) != null)
{
DataRow newRow = dt.NewRow();
newRow["Server"] = line.ToString();
dt.Rows.Add(newRow);
}
}
Dts.Variables["ServerListing"].Value = dt;
}
catch (Exception ex)
{
MessageBox.Show(ex.Message.ToString());
}
Dts.TaskResult = (int)ScriptResults.Success;
}
To complete the shredding of the variable process, a Foreach Loop Container is used with an enumerator, Foreach ADO Enumerator. This is the same method of parsing record sets used in past years with scripting languages. Once the Foreach ADO Enumerator is set, the ADO object source variable option is made available. Select the variable to be read in this drop down list. The last major configuration is to set one or more variables that will be populated by the enumeration of each row in the object variable. In the case of the container that will read the server list, only one column per row is available. So only one variable mapping is required.
For a detailed article on shredding variables, read “Using Variables as a source in a Data Flow Component” by Josef Richberg (Blog | Twitter).
Data Flow
With the method and designs we have chosen to do this SSIS package, the data flow that will read the data and export to the file, will need to utilize a script component as the source. The script component as a source in a data flow task allows us to perform several code specific transformations, such aslogic or even data extraction. Earlier we shredded the secondary object variable into several matching variables. Those variables are now required to be the source in an output format. This output format is then passed to the destination. Before being able to set the variables as output values, the output columns need to be defined. For each variable, or column that is needed as an output column, the column needs to be defined in the Inputs and Outputs page of the script transformation editor.
Using the Add Column button, add a column into the Output Columns for each matching variable that was created and populated from the Foreach Loop over the object variable.
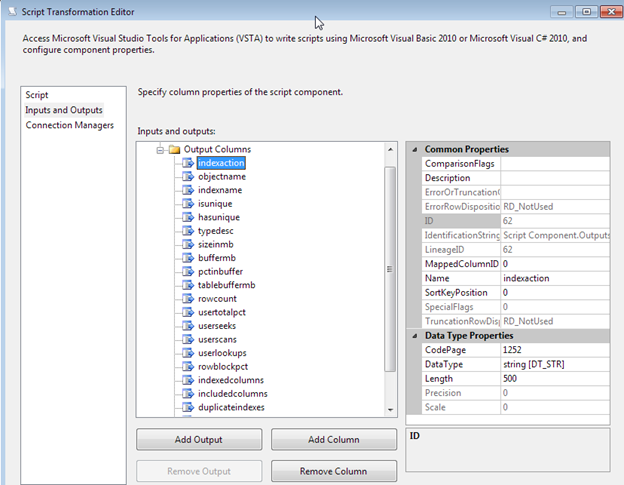
Remember to ensure the length and data types of these columns are accurate. Lengths that are too small can cause truncation errors and lengths that are too large can cause unwanted performance problems. In some cases, data types can be explicitly converted at the time of the buffer moving in the data flow, but this value should match to ensure no performance problems or errors on casting the data types occur. Remember, casting from unicode to non-unicode will always generate an error. In flat file and many systems or other data sources, Unicode will be the default.
After the output columns are defined, the next step is to add the variables as write available variables to the script component and then add the code needed to move the variables to the output columns or output buffer.
IDTSVariables100 var = null;
VariableDispenser.LockForWrite("User::buffer_mb");
VariableDispenser.LockForWrite("User::duplicate_indexes");
VariableDispenser.LockForWrite("User::has_unique");
VariableDispenser.LockForWrite("User::index_action");
VariableDispenser.LockForWrite("User::index_name");
VariableDispenser.LockForWrite("User::indexed_columns");
VariableDispenser.LockForWrite("User::is_unique");
VariableDispenser.LockForWrite("User::object_name");
VariableDispenser.LockForWrite("User::overlapping_indexes");
VariableDispenser.LockForWrite("User::pct_in_buffer");
VariableDispenser.LockForWrite("User::related_foreign_keys");
VariableDispenser.LockForWrite("User::related_foreign_keys_xml");
VariableDispenser.LockForWrite("User::row_block_pct");
VariableDispenser.LockForWrite("User::row_count");
VariableDispenser.LockForWrite("User::size_in_mb");
VariableDispenser.LockForWrite("User::table_buffer_mb");
VariableDispenser.LockForWrite("User::type_desc");
VariableDispenser.LockForWrite("User::user_lookups");
VariableDispenser.LockForWrite("User::user_scans");
VariableDispenser.LockForWrite("User::user_seeks");
VariableDispenser.LockForWrite("User::user_total_pct");
VariableDispenser.LockForWrite("User::included_columns");
VariableDispenser.GetVariables(out var);
Output0Buffer.AddRow();
Output0Buffer.buffermb = (String)var["User::buffer_mb"].Value;
Output0Buffer.duplicateindexes = (String)var["User::duplicate_indexes"].Value;
Output0Buffer.hasunique = (Int32)var["User::has_unique"].Value;
Output0Buffer.indexaction = (String)var["User::index_action"].Value;
Output0Buffer.indexname = (String)var["User::index_name"].Value;
Output0Buffer.indexedcolumns = (String)var["User::indexed_columns"].Value;
Output0Buffer.isunique = (Int32)var["User::is_unique"].Value;
Output0Buffer.objectname = (String)var["User::object_name"].Value;
Output0Buffer.overlappingindexes = (String)var["User::overlapping_indexes"].Value;
Output0Buffer.pctinbuffer = (String)var["User::pct_in_buffer"].Value;
Output0Buffer.relatedforeignkeys = (String)var["User::related_foreign_keys"].Value;
Output0Buffer.relatedforeignkeysxml = (String)var["User::related_foreign_keys_xml"].Value;
Output0Buffer.rowblockpct = (String)var["User::row_block_pct"].Value;
Output0Buffer.rowcount = (String)var["User::row_count"].Value;
Output0Buffer.sizeinmb = (String)var["User::size_in_mb"].Value;
Output0Buffer.tablebuffermb = (String)var["User::table_buffer_mb"].Value;
Output0Buffer.typedesc = (String)var["User::type_desc"].Value;
Output0Buffer.userlookups = (String)var["User::user_lookups"].Value;
Output0Buffer.userscans = (String)var["User::user_scans"].Value;
Output0Buffer.userseeks = (String)var["User::user_seeks"].Value;
Output0Buffer.usertotalpct = (String)var["User::user_total_pct"].Value;
Output0Buffer.includedcolumns = (String)var["User::included_columns"].Value;
var.Unlock();
Output0Buffer.SetEndOfRowset();
The code above locks all the variables and then assigns them accordingly to the output buffer columns. One completed, the variables are unlocked and the row is sent through.
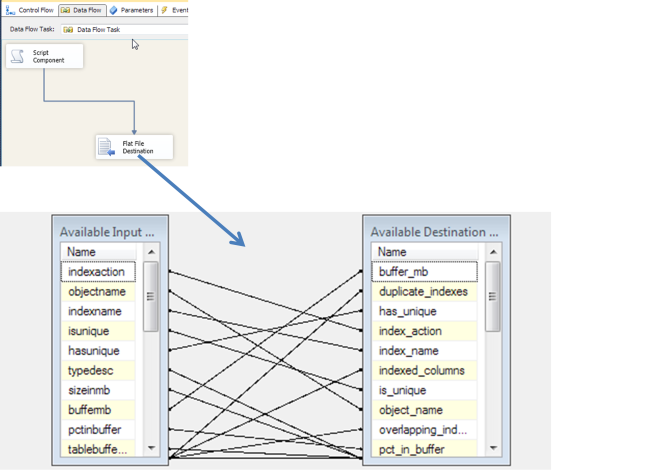
At this point, mapping the output columns to the flat file destination columns is all that is needed.
Configuration File
Add a configuration file to the package to complete the dynamic and mobile setup of the package. The configuration file will take the server list and database list file names. It should also contain a default database, in most cases master, for administrative operations.
For detailed information on using and setting up configuration files, refer to “Making SSIS Dynamic: Configuration Management”
Execution

This package runs well and performed the exact task that was required of it. The shredding of the object variables completed, the output buffer created for each row and loaded into the file destination. The files were also created for each task that we wanted based on each SQL Server Instance.

Review and Problems with this Design
In review, we’ve talked about how to do several things to make this package possible.
- Dynamic file lists for reusable package executions on several SQL Server Instances
- Shred variables and map them to multiple variables for each column returned by using the Foreach Loop Container and the ADO Enumerator
- Script component as sources and populating the output buffer with variables.
Although this design works well on databases with a lower number of indexes and databases used less frequently, the design is inherently poor on performance overall if a large database is a factor. In the tests I made, the least utilized and smallest database resulted in a relatively quick total execution time. Using a larger more realistic database, the total execution time suffered drastically from the design.
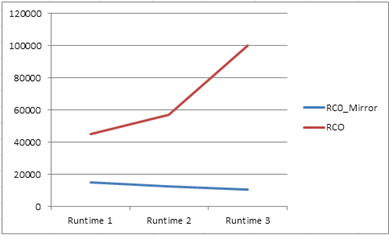
Based on three executions of the package for each instance set in the Server List file.
We went through this design to show methods that could be used. We also went through the design to show that even when coming from something that was successfully execute and results validated, the overall achievement and performance factor was poor. Due to those factors, this package will be redesigned to better use SQL Server and the Data Flow task in SSIS. In the next article we will build that package from scratch and show each step that is involved.
Use this design when there is a need. Several cases require the shredding of variables and utilizing them as a data source. Be sure that when utilizing either a row-by-row operations or a one row in type situation, to measure your performance on all database sizes.


