


Article, Automating Index Statistics Collection, went over a method to automate running a script authored by Jason Strate. The script is a comprehensive collection of index statistics and usage details that allows a DBA or designated administrator of SQL Server one place to go for review. SSIS was used to execute the script on a list of SQL Server Instances and databases specified in flat files. The overall design of the SSIS Package was OK. Given the shredding method and row-by-row export to flat files of the results, the overall run time could only handle a relatively small amount of total indexes and proposed indexes.
Since the package couldn’t handle larger, more realistic databases and index usage, the SSIS package was redesigned. The new design takes advantage of the Data Flow Engine more. This is done by preparing the full results from the script and exporting those results, not row-by-row, but by taking full advantage of the total room allowed in the given buffer.
Re-Design
The flow of the design does not change so the previous article’s design can still be utilized. The method that is used in SSIS changes.
The initial shredding of variables using Foreach Loop Containers will remain. This method works well for pulling in the contents of files so we can alter connections for each row returned. This is done in the connection by assigning a variable the value returned from each enumeration of the ADO object. In the connection manager, setting the variable that is changed on each enumeration as the connection string by using an expression completes the dynamic ability.

With the method that we are moving to, there is the need for two distinct connection managers that handle a variable for dynamically connecting to specific SQL Server Instances. The reason for the second connection manager is the need for the Keep Existing option set to True. We will discuss why this is needed in a minute. First, let’s discuss the overall design.
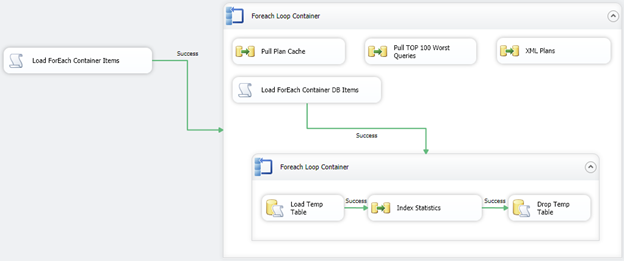
Below is a snapshot of the control flow. The same script task is utilized to pull the file contents that contain the server listings into a variable. This moves to the Foreach Loop Container and then upon each enumeration, executes each task within the Foreach loop.
The tasks in the container now contain four unique data flow ad transformations.
- Pull Plan Cache – pulls the server for the entire plan cache. Note, large plan caches can seriously affect the buffer overflowing to disk. Be sure this is really a requirement that can prove valuable to you and your SQL Server instance.
- Pull TOP 100 Worst Queries
- Pull Plan’s XML data. – Data Flow 1 and 3 can be combined. For performance analysis, we left it in here for now.
- The final process handles running the index analysis script. Another script task handles pulling the contents of the file with the database list to run the script on. Then moves to a Foreach Loop to shred the ADO object. Within the Foreach Loop Container is the method that will require our second connection manager.
The fourth level, the index analysis script, is the primary new design that we will use. In this example, we will use another common method in SSIS. A global temporary table will be created using an Execute SQL Task and then the select on that table will be the source in a Data Flow task. In order to accomplish this, a connection manager that retains the same connection through the process must be used. To do this, set RetainSameConnection to True in a connection manager named, Keepconn. In SSIS, when a data flow task is completed or any use of the connection manager, a release connection is called. In total, this can happen several times through a full cycle of the package’s runtime. In order to retain the same connection through the runtime or a specific sequence of tasks, the connection is forced to not be recycled or released. This retains the temporary table given the connection has not ended and prompted for a removal of the table.
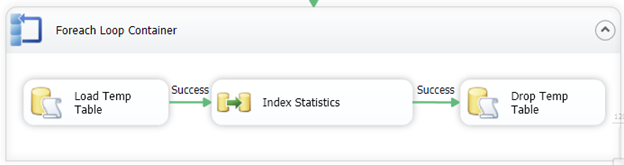
The steps above work as a sequence that does the overall same process as the design in the previous article. However, the creation and population of the temporary table prior to the data flow, allows for the data flow to work as efficiently as designed and to its best capabilities. This is the foundation of a data flow: Data in, transform, and data out.
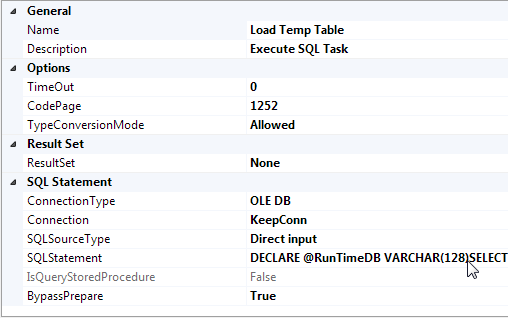
The BypassPrepare is still required in the Execute SQL Task because the temporary table does not exist to be validated prior to runtime. Utilizing the KeepConn, enter the statement that will create and load the temporary table.
In order to take into account the multiple databases that index statistics should be collected from, pass a parameter into the SQLStatement. This is done by altering the statement to use a variable in T-SQL instead of the DB_ID() function.
DECLARE @RunTimeDB VARCHAR(128)
SELECT @RunTimeDB = [Name] FROM sys.databases WHERE [name] = ?
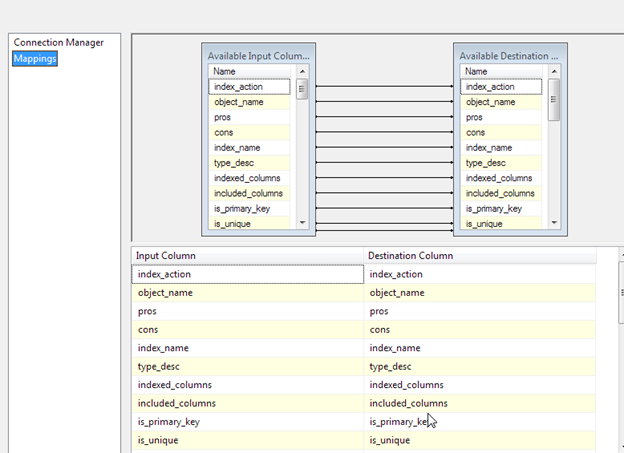
In the data flow task, all that is needed is to map the results to the flat file destination.
Finally, add a task to clean up the temporary table. Normally, the temporary table would be removed on its own in SQL Server later in the connection’s life cycle. However, keeping to the code of conduct, “If you make a mess, clean up after yourself” the table should be removed manually in a final step.
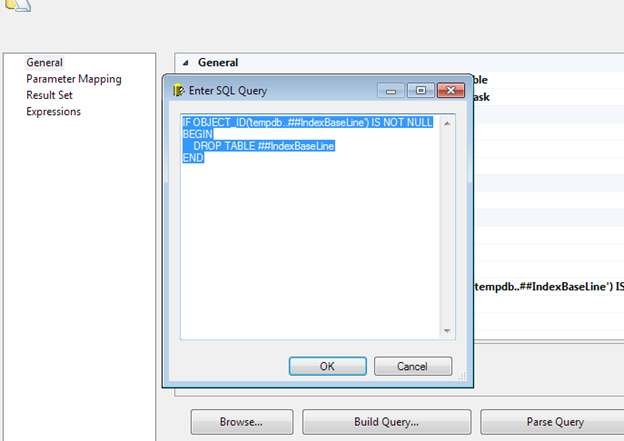
To do this, we check to ensure the table exists before calling a DROP TABLE statement.
IF OBJECT_ID('tempdb..##IndexBaseLine') IS NOT NULL
BEGIN
DROP TABLE ##IndexBaseLine
END
Try it out

The overall execution in the first design resulted in the following.
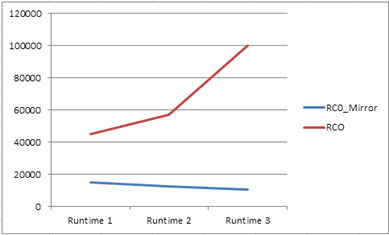
With this redesign, the same test results in the following.

The runtime on each test is a remarkable difference from the first SSIS Package design. This is, in a way, the same as tuning a really bad execution plan but for SSIS, we tuned if our flow is right first. The query takes over 20 minutes, but after adding an index or two, query time goes to a second or two.
As expected, the files are created and populated with the information we can use to start turning on the “fast” button in SQL Server by ensuring indexing is done correctly.

Recap of the life cycle of this package
We accomplished a lot in these two articles. Shredding variables, temporary tables in SSIS, dynamic connections to multiple instances based on one connection manager, changing database context in the middle of execution based on more dynamic methods and an overall, better design based on a first, not well performing one.
The best lesson we can take away is, when a design or even statement works great, test it on volume that you may run into. Even if the volume isn’t reality yet in your facility, it may and probably will, change over time, and your implementation should withstand that growth.


