


I was asked the other day, “Is there really a difference in performance loading data into newer versions of SQL Server in the same process?” The question really has many variables that need to be answered prior to even considering an answer. Such variables are the data architecture, I/O setup for each, loading method such as bulk loading, SQL database and SQL Server Instance configurations, pipe and network latency, and on. As you can see, to really answer this, you need to take much into account.
Regardless of how many variables are in place, we could conceptually say that the new engines should be able to handle loading data better as the engines have evolved. To look at that, we could do a fairly basic test in a controlled setting. Take the following test and results for example.
- Windows Server 2012 with 8GB RAM running on one SSD drive for data and transaction logs
- SQL Server configured with 3200MB of maximum memory, MAXDOP of 1 and the remaining configuration settings essentially set to defaults.
To manage a loading scenario, using SSIS 2012 and the data flow engine is performed. This is done based on the question of the processing of data loading data into the different versions of SQL Server. However this may seem basic, it is a common scenario when moving data around for reporting solutions and integrating data with multiple versions of SQL Server on large environments.
The package takes on three data flow tasks, run in parallel. These tasks pull from three different tables that are identical to the AdventureWorks2012 table SalesOrderDetailEnlarged. To find out more on how to create the larger SalesOrderDetail, look here. This SSIS package appears simply as,

Each data flow has its own source and destination connection manager as an OLEDB provider. Each connects to a fourth SQL Server 2012 instance that contains the three databases with the copy of SalesOrderDetailEnlarged in each. The destination is specified as a unique SQL Server Instance with the latest build number and a destination identical to the source. Internally to each data flow task, it appears as,
Each destination puts a table lock for bulk loading and a buffer max rows setting on the data flow of 100,000 rows.
Overall, this is an extremely basic test but one that mimics many scenarios that are written for dumping data over to other databases. Hence, another reason the question came up.
Executing this package in a series of 6 executions, I found the results to be quite interesting. To monitor how long each task was taking, I chose to look at logging and the entire process from evaluation to completion. To do so, setup another connection manager to another SQL Server instance for logging. Then configure logging to SQL Server so the SYSSSISLOG table is created and logged to for each available event. Once this is done, after the package is competed, querying the SYSSSISLOG table like below should represent a sound estimate of the total times for each task.
SELECT '2008 R2'
,datediff(ms, min(starttime), max(endtime))
FROM sysssislog
WHERE source = 'SQL 2008 R2'
UNION
SELECT '2008'
,datediff(ms, min(starttime), max(endtime))
FROM sysssislog
WHERE source = 'SQL 2008'
UNION
SELECT '2012'
,datediff(ms, min(starttime), max(endtime))
FROM sysssislog
WHERE source = 'SQL 2012'
Fully expecting SQL Server 2012 to be lower in overall times, the below results should prove interesting.
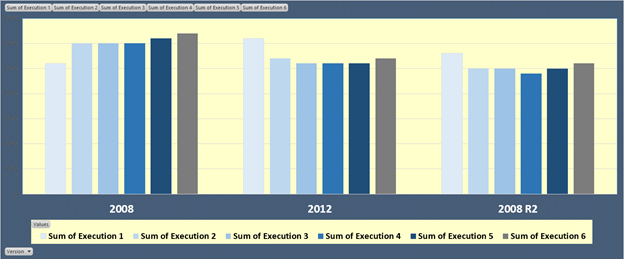
Recall, this is an estimation and a theoretical test since we have many more variables we should, and probably will, need to consider. But in this test, we can see that in the 6 executions, SQL Server 2008 R2 actually outperforms 2008 or 2012 as a destination. 2012 is roughly in the same area, only 1000 milliseconds or so off form 2008 R2. 2008, however, has a much higher loading time than the new versions.


