


I received an email the other day asking why, when running SHOW_STATISTICS, a person was always seeing the primary key in the statistics column density and other output, when the primary key was not part of the index the statistics were created from.
This is a great question and relates to an article I’m writing on selectivity and ordering in the creation of an index while writing queries. I thought a quick post would be great on it, since the answer isn’t truly standing out when you search for the reason statistics on nonclustered indexes will always contain the primary key or unique constraint column (on a table that is clustered).
Index Structure
The first part of this is the index the statistics were created off of. If the table being indexed is a clustered table, as shown in listing 1, the unique row indicator for that table will become the primary key. In our case, Col_ID is now the row indicator for the table or referenced to the actual data row in case the need arises.
CREATE TABLE SelectivityIndexOrder (
Col_ID INT IDENTITY(1,1) PRIMARY KEY,
Col_String VARCHAR(25),
Col_Date DATETIME DEFAULT GETDATE(),
Col_TinyInt TINYINT,
Col_BIT BIT DEFAULT (0)
);
DECLARE @LOOP INT = 1
WHILE @LOOP <= 1000
BEGIN
INSERT INTO SelectivityIndexOrder (Col_String,Col_TinyInt)
SELECT 'String value for row ' + CAST(@LOOP AS VARCHAR(4)), 2
SET @LOOP += 1
END
WHILE @LOOP <= 2001
BEGIN
INSERT INTO SelectivityIndexOrder (Col_String,Col_TinyInt)
SELECT 'String value for row ' + CAST(@LOOP AS VARCHAR(4)), 3
SET @LOOP += 1
END
CREATE NONCLUSTERED INDEX IDX_BIT ON SelectivityIndexOrder (Col_BIT,Col_date)
INCLUDE (Col_String)
Listing 1
What this means is, in the case of the creation of a nonclustered index, the column(s) that are being indexed are part of the index (the leaf node values). The other structural part of a nonclustered index on a table with a clustered index is the row indicator. In a clustered, unique situation, the best value for a row indicator is the clustered index. This is the pointer back to the actual data row.
Now that we know how the clustered values are used in a nonclustered index, let’s take a look at the structure of the nonclustered index. Using DBCC IND and PAGE, we can drill down to see the actual utilization of the keys.
DBCC IND('QTuner',"SelectivityIndexOrder",2)
GO

Figure 1
DBCC TRACEON(3604)
DBCC PAGE('QTuner',1,434394,3)
GO

Figure 2
As shown above, the IND results give us a page number of 434394 that we can look at. Running DBCC PAGE on that page results in the output in figure 2. This shows a column value of the Col_ID (key) as the pointers back to those rows.
Now, knowing that statistics are generated automatically for indexes, this would enforce the need for the statistics to not only be created on the Col_BIT column, but in this case, on the Col_ID column as well.
Using SHOW_STATISTICS, we can see that happening on our example, as shown in Figure 3.
DBCC SHOW_STATISTICS ("SelectivityIndexOrder", IDX_BIT);
GO
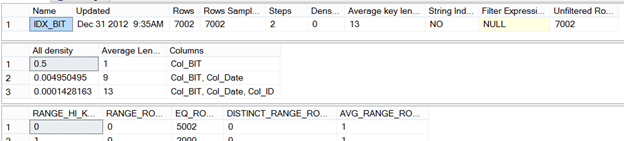
Figure 3
As with any structure of statistics, the same rule of the histogram being created only for the first column still applies here. This moves into the topic of selectivity and the future post mentioned in the beginning of this article. Notice the density is stored for the other columns combined. In our NC index, we have Col_BIT and Col_Date. In order to store the row indicator, then, Col_ID is part of the statistics.
What about HEAPs?
As shown up until now, the reason the key is stored in the statistics is due to the key being the row indicator in the nonclustered index. SQL Server needs this to effectively look back to the data rows. What would happen to the statistics if all of this was based on a HEAP table (a table not clustered)?
To test this, use listing 2.
CREATE TABLE SelectivityIndexOrderHeap (
Col_ID INT IDENTITY(1,1),
Col_String VARCHAR(25),
Col_Date DATETIME DEFAULT GETDATE(),
Col_TinyInt TINYINT,
Col_BIT BIT DEFAULT (0)
);
DECLARE @LOOP INT = 1
WHILE @LOOP <= 1000
BEGIN
INSERT INTO SelectivityIndexOrderHeap (Col_String,Col_TinyInt)
SELECT 'String value for row ' + CAST(@LOOP AS VARCHAR(4)), 2
SET @LOOP += 1
END
WHILE @LOOP <= 2001
BEGIN
INSERT INTO SelectivityIndexOrderHeap (Col_String,Col_TinyInt)
SELECT 'String value for row ' + CAST(@LOOP AS VARCHAR(4)), 3
SET @LOOP += 1
END
CREATE NONCLUSTERED INDEX IDX_BIT ON SelectivityIndexOrderHeap (Col_BIT,Col_date)
INCLUDE (Col_String)
GO
DBCC SHOW_STATISTICS (SelectivityIndexOrderHeap, [IDX_BIT]);
GO
CREATE NONCLUSTERED INDEX IDX_BIT ON SelectivityIndexOrderHeap (Col_BIT,Col_date)
INCLUDE (Col_String)
GO
DBCC SHOW_STATISTICS (SelectivityIndexOrderHeap, [IDX_BIT]);
GO
Listing 2
The output from listing 2 is shown in figure 4.

Figure 4
Notice in figure 4 that the key, which doesn’t exist on the table, is shown. This goes back to the same reasoning of why a key is included in the statistics of a clustered table. With a HEAP, however, the row indicator is a pointer directly to the data row. In listing 3, running DBCC PAGE on the first page shown, we can see how to find the data.
DBCC IND('QTuner',SelectivityIndexOrderHeap,2)
GO
DBCC TRACEON(3604)
DBCC PAGE('QTuner',1,434400,1)
GO
Listing 3

Figure 5
I don’t want to dive too far into the PAGE output as it is out of scope. What I will point out is the row outlined being the slot and the offset. To really dig into PAGE, read, “Inside the Storage Engine: Anatomy of a page” by Paul Randal.
For the HEAP table and the nonclustered index, there is a need for the extra step, unlike the step utilizing a key in the clustered table, to utilize the row indicator directly back to the data rows in the HEAP structure. Since this is not an actual column, that would not show in statistics.
Summary
As we’ve covered, the reason a you will see the primary key or unique keys in statistics, even when you do not specifically add them to a nonclustered index, is due to the need to have the row indicator as part of the index.


