


I often run across databases that store files, images, and all sorts of large object data types, better known as LOBs. These databases will typically become problematic as storing these types of objects in a relational database has some performance problems with it. Some of those performance problems revolve around excessive server resource consumption and limited indexing abilities which make requesting or querying the data as painful as the performance of inserting data into them is. Although the concept of storing these objects in SQL Server is mostly a negative design to most administrators, it does happen and there are valid reasons, such as security and retention of the objects. For example, in some medical related systems, files can contain patient related information and fall under strict guidelines and security restrictions. Most administrators that have worked in a hospital or a pharmaceutical system that provides Rx products have run into these strict guidelines and security measures. Placing these files into a SQL Server database allows for a deeper security model as well an easily obtained recovery model and longer retention period. Now, the cost of disk for a database server is typically higher than a file-based system’s disk cost. That alone can outweigh file layers that can be used with third party tools in order to meet the same security and recovery needs. Weigh those options heavily when in a designing stage in which files are part of the overall design and needs.
Even with options available, the fact remains, the LOB data types will be found and we need to deal with them so we can make the user experience as good as it can be with the data services. Recently I was reading an excellent article on SQL Server Pro by Paul Randal that discussed a method for achieving index seeks when LOB data is involved. Having been in many data service layouts that have used LOB data types, the tip that Paul provided was excellent, simple, and effective.
To show the effects of using the method Paul discussed, I will create a table that mimics what would be in a real –world production database that needs to store Word documents. The table will consist of an identity as a primary key, a user name that is associated with the file inserted, and the section of the data from the LOB data for each row inserted.
Create the table, PerfLOB
CREATE TABLE PerfLOB
(ID INT IDENTITY(1,1) PRIMARY KEY,
USERNAME VARCHAR(155),
LOBVAL VARBINARY(MAX),
SUB_CONTENT AS CONVERT(VARCHAR(100),SUBSTRING(LOBVAL,1,100)))
GO
For testing purposes, the below statement will insert 1000 copies of a Word document found on the system this was tested on into PerfLOB. Replace the Word document path with a Word document you have on your testing system.
INSERT INTO PerfLOB (USERNAME,LOBVAL)
VALUES (SUSER_SNAME(),(SELECT * FROM OPENROWSET(BULK N'C:NoSecColumStoreIndexBasics.docx', SINGLE_BLOB) AS guts))
GO 1000
(Warning: this insert will take some time due to the LOB insertions.)
Review the contents by using a select statement and the LEN() function. Set Statistics IO on at this point so you can better see the system requirements to fulfill the query.
SET STATISTICS IO ON
SELECT LEN(LOBVAL), SUB_CONTENT FROM PerfLOB
As you can see, there isn’t much value in looking at the results of a query like this and the actual LOBVAL column, although the length values returned of the LOBVAL column do have some value for knowledge of what is being taken.
At this point, there are no indexes on the table other than the primary key’s clustered index. The clustered index will be used heavily due to the lack of nonclustered indexing to support any queries that you want to run on the table. Since the clustered index contains the entire table or columns, its use here is ineffective in truly helping the query to perform as well as its potential. For the query executed to obtain the length and LOBVAL column, we can see that an index scan on the primary key is being performed. This may seem ok, but remember that an index scan on the clustered index at this point is the same as a table scan.
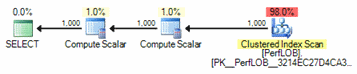
Further investigation shows a large number of lob logical reads to return the results.
Table ‘PerfLOB’. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 7, lob logical reads 726000, lob physical reads 0, lob read-ahead reads 336000.
This query requires an extreme amount of resources to complete, as we’ve shown monitoring the IO statistics through these examples. Working with the substring method that Paul discussed in his article, we will take advantage of the computed column that was created on the table, SUB_CONTENT. This column holds the first 100 characters of the LOB column for each row.
Now, let’s take a look at something that could be a requirement in a production environment for updating the PerfLOB table. The USERNAME column must be updated so ownership of the documents are maintained. This could be done with the following query.
DECLARE @Doc VARBINARY(MAX)
SET @Doc = (SELECT BulkColumn FROM OPENROWSET(BULK N'C:NoSecColumStoreIndexBasics.docx', SINGLE_BLOB) AS guts)
UPDATE PerfLOB
SET USERNAME = SUSER_SNAME()
WHERE LOBVAL = @Doc
GO
IO Results – Table ‘PerfLOB’. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 86000, lob physical reads 0, lob read-ahead reads 0.
The update above that is relying on searching for the matching document, like the query to obtain length and the LOBVAL column, takes an extreme amount of resources and time to complete. Given a larger table, more resources would be required and there would be lengthy locking time on the table. We can use the substring and computed column method to make this more efficient.
We have the SUB_CONTENT column and can make it the key column in the index, we can use the INCLUDE option to include the actual LOB column as a non-key column; LOBVAL.
CREATE NONCLUSTERED INDEX IDX_LOGSTRING ON PerfLOB (SUB_CONTENT) INCLUDE (LOBVAL)GO
As with the earlier warning regarding the time it will take to create the table and insert 10,000 rows into it, any mass change or work that is required on a table like the PerfLOB table, will take some time. This is critical to estimating the time needed to perform these actions. While the index is being generated or other tasks may be running, the locks on the table will prevent other transactions from accessing them or lower level locks being placed on them. Be sure to plan the time when the table will not be accessible, as blocking may occur or users will experience a drastic decrease in overall performance.
When you store LOB data in SQL Server, it is stored in LOB_DATA and in a page type of its own designated as Text/Image. The page is store along with the IN_ROW_DATA page in a sense utilizing a 16 byte pointer that is used to refer to the LOB_DATA in the page.
We could visualize this as
Something to consider about the storage needs for and time of a nonclustered index creation is that the LOB_DATA page will exist in the nonclustered index. We can take a closer look at this by running the following query to dig into the pages.
select obj.name, idx.name, parts.index_id, parts.partition_id, parts.hobt_id, all_units.allocation_unit_id, all_units.type_desc, all_units.total_pages from sys.objects obj inner join sys.partitions parts on obj.object_id = parts.object_id inner join sys.allocation_units all_units on all_units.container_id = parts.hobt_id inner join sys.indexes idx on parts.index_id = idx.index_id and obj.object_id = idx.object_id where obj.name = 'PerfLOB'Notice that there is a LOB_DATA page type for both the clustered and the nonclustered index. Also notice the number of pages in each. Since the clustered index includes all the data and the nonclustered, even with the use of the INCLUDE and non-key columns does not, there is a difference in the overall page count. There will be performance gains from using the nonclustered index, but an extensive amount of resources are still needed to create the index.
Now that the nonclustered index has been created on the computed column, run the same query as earlier, with minor changes to utilize the computed column as the predicate. Alter the query as shown to force the use of the new nonclustered index with an index hint.
DECLARE @SUBString VARCHAR(100) DECLARE @PK INT SET @SUBString = (SELECT CONVERT(VARCHAR(100),BulkColumn) FROM OPENROWSET(BULK N'C:NoSecColumStoreIndexBasics.docx', SINGLE_BLOB) AS guts) SET @PK = (SELECT TOP 1 ID FROM PerfLOB WITH (INDEX=IDX_LOGSTRING) WHERE SUB_CONTENT = @SUBString) UPDATE PerfLOB SET USERNAME = SUSER_SNAME() WHERE ID = @PK GO(Note: the use of TOP 1 is added given the testing example and the documents all being the same. The documents would be unique data in a normalized table.)
Looking at the execution plans generated from the new update statements, we can see the plan looks much more effective.
Further, the IO generated by the update statement has significantly been reduced.
Table ‘Worktable’. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 59, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
Table ‘PerfLOB’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
Table ‘PerfLOB’. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Summary
As Paul said in the original article that sparked this blog, this isn’t a truly ideal situation but is very effective when the exact circumstances arise. Remember to maintain the indexing that is created as well as indexing, storage and resource utilization when LOB data types are stored in your databases. These tricks are always good to have, but at the same time, using them appropriately and effectively is the primary key to better data services.






