


Compression and Segments
Columnstore indexes are efficient due to a few primary characteristics they rely on. One of those characteristics is compression. When building a columnstore index, the structure of the table (be it HEAP or clustered B-Tree) is utilized to build the actual columnstore index. After this point, the table itself isn’t really utilized in the terms of normal engine processing as we’ve known it with other indexing. While the columnstore index is being built, data is distributed, if you will, across groups called segments. Within each segment, there will be up to a million rows. Later, we’ll take a look at a segment and what information we can see from it but the overall structure of a segment is based off a grouping of data with a minimum range to maximum range.
Although the minimum and maximum ranges are nothing like a histogram and the RANGE_HI_KEY, we can use that reference to understand better what it allows SQL Server to do in order to make it highly efficient for finding data. Imagine a column holding a sales dollar amount, with values that range from $1 to $3000. In a segment, the range would be portrayed as just that, the segment contains data for that column ranging from 1 to 3000 dollars. Now, take a query that wants the sales amount that matches $200. Any segment that holds a range of greater than $200 is quickly dismissed and the segment that has the range, 1 to 3000, is easily grabbed and pulled down.
Further into the creation of the columnstore index, compression is used to an extremely high degree with the xVelocity technology and compression algorithms. Although this is not the same as row or page compression in SQL Server, we already know from experience that compression in SQL Server has made vast improvements in performance related to s I/O and internal data storage. Columnstore indexing is at its best when used with data that is redundant. Fact tables are the best example. A value may be repeated a great deal across the column. This allows for the column I/O performance to be enhanced greatly by compressing the data at a high level.
Method in which data is retrieved, compression and overall storage method in segments all are factors that lend reasoning to why creating a columnstore index is truly effective when all the columns in a table are included in the columnstore index. Essentially, the structure allows no difference in efficiency on a large table when there are some or all of the columns included. With this, the true efficiency will mostly be found with large tables and not much benefit in small tables with columnstore indexing.
Dictionaries
Dictionaries are a mapping to segments in a columnstore index. Think of a dictionary in a columnstore index in the way a map is drawn. The dictionary is an entire continent and holds several latitude and longitude points that refer to states or inner countries (segments). Columnstore index dictionaries make it possible to pull only segments that are needed when a plan is created and query executed. In a way, in terms of SQL Server file structure, we could look at a dictionary as a file group and segments are the files that are contained in the file group. Although this comparison isn’t completely accurate, it does allow a visualization we can form to see how these two primary objects, segments and dictionaries, relate to each other.
Digging Columnstore Index Metadata
Now that we’ve discussed some internals of the columnstore index, there are catalog views that allow reviewing the metadata and relations of them.
In earlier public releases of SQL Server 2012 (Denali) and documentation and blogs, there were three primary catalog views that were discussed for investigating information behind the columnstore index. The three catalog views
The views are useful but given columnstore indexing and the needs compared to row store indexing (clustered, nonclustered), the use is more informational and not based on maintenance as much other than space allocation. This is part in thanks to columnstore and the xVelocity technology itself. Eric Hanson authored a Columnstore Index FAQ on the wiki of Technet that also contains a very good query to return size in segments, dictionaries and partitioned information. The output from Eric’s query can be seen below on the columnstore indexes that were created from, “Columnstore Index Basics”.

Relating segments and dictionaries
Relating the two catalog views, sys.column_store_dictionaries and sys.column_store_segments is relatively straight forward when reviewing the raw data returned from both views. Run the following two select statements on the AdventureWorkdDW2012 database that hold the columnstore indexes created from, “Columnstore Index Basics”. (We’ll assume AdventureWorksDW2012 and the indexes exist from here.)
select * from sys.column_store_dictionaries
select * from sys.column_store_segments
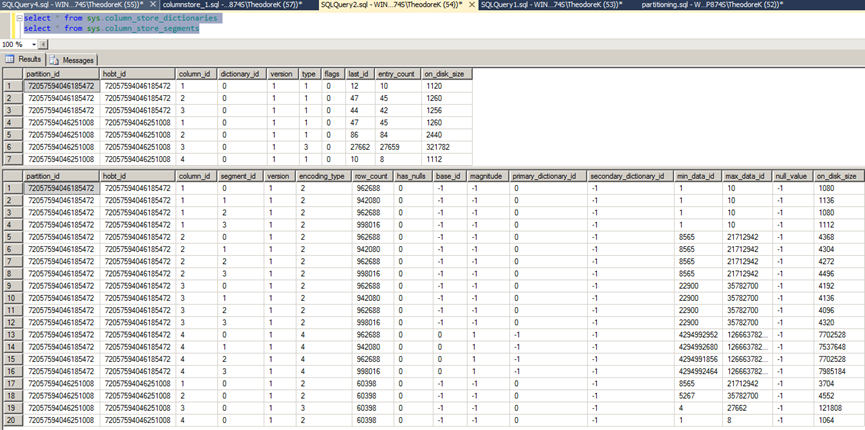
Reviewing the results, the on_disk_size typically draws attention right away. This column will undoubtedly be useful in determining the space utilized by both the dictionaries and the segments that make up a columnstore index. This can also be seen in Eric Hanson’s query to return the various size statistics of the segments and dictionaries by calculating from the bytes value in the on_disk_size column and referring back to the column_id it specifically relates to.
It can also be seen from the top results from the dictionaries catalog view that each column_id relates back to the segements view to determine the actual number of segments a column contains.
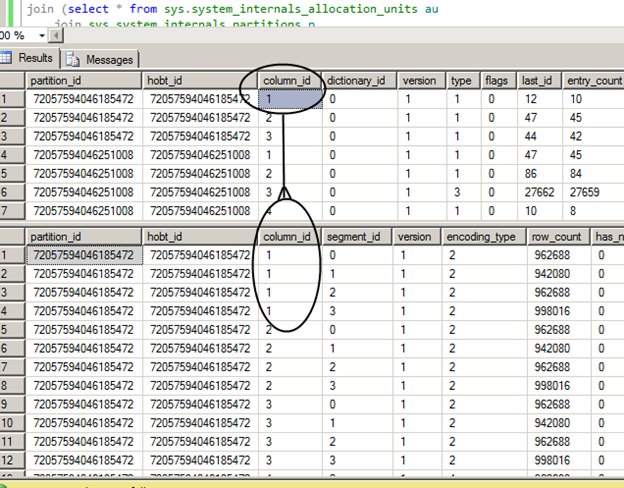
In this case, column_id 1 has 4 segments and each segment contains around a million rows. Each segment in a columnstore index will contain up to a million rows. Each segment can be identified by the column_id + segment_id.
The next part that holds value is the range values. This was discussed earlier and is the method in which columnstore indexes are used to make them efficient for not allowing unwanted data to be pulled into memory.
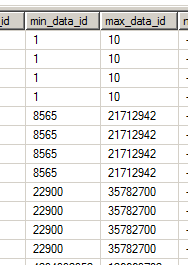
In the above image, the range for column_id 1 (column_id 1 is the first 4 rows) is a minimum of 1 and a maximum of 10. We can determine the actual column_id and the column name referred to by adding in the partitions view to locate the actual partition, segment and then column.
SELECT segs.on_disk_size, cols.name
FROM sys.partitions AS parts
JOIN sys.column_store_segments AS segs ON parts.hobt_id = segs.hobt_id
JOIN sys.columns AS cols ON cols.object_id = parts.object_id and cols.column_id = segs.column_id
WHERE segs.COLUMN_ID = 1
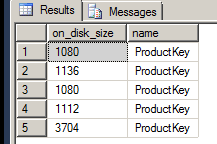
Referring back to the min and max range and the block they are in, we do not know the column name that this refers to and the minimum and maximum ID in the block of segments the data is stored in. The table this exact columnstore index was created on was small and only shows blocks of four segments. Segments can be larger blocks though.
Index Stats
Moving to the view, sys.column_store_index_stats, you’ll quickly find that the object doesn’t exist any longer in SQL Server 2012. Instead, the same index stats DMV, sys.dm_db_index_usage_stats, can be used in RTM to see the statistics information of a columnstore index. The column_store_index_stats view was seemingly dropped and functionality or information results were moved to index_usage_stats.
select
object_name(stats.object_id) [Table or View Name]
,idx.[name]
,stats.user_scans
,stats.last_user_scan
from sys.dm_db_index_usage_stats stats
join sys.indexes idx on stats.index_id = idx.index_id and stats.object_id = idx.object_id
WHERE idx.type_desc = 'NONCLUSTERED COLUMNSTORE'

Columnstore indexes cannot use a seek operator so the only information that is valued here is the scans counts and the last scan. This is an important piece of information when tuning an execution plan. Normal tuning practices will force someone to look to obtain a seek operator but with columnstore indexing, the segments are always scanned given how they are stored. With this, the index can be reviewed periodically to determine if the index is performing an actual use to the database. Columnstore indexes use compression by default making them perform better but they still take space in the database. If the index is not being used, it should be treated like any other index and consider its removal. Now, typically the columnstore index would be an OLAP based object (data warehouse). With OLAP systems, queries may be run once a month or even once a year. With OLTP or transactional based systems, an index’s value has a slightly different measurement. If the index isn’t used in days, it is flagged as a possible index to be removed. Again, this all becomes a result of a formula created based on the specific databases use. The formula cannot be written and broadcasted in a static form. One index that is used once a month may be so valuable that is requires the added resources to maintain on a highly transactional table; while another index that is run once a month doesn’t share the value. Other methods such as creating the index prior to running the query that the index will benefit the execution plan generated by the optimizer may be an overall better solution.
Move Index DMV Results
Although operational_stats will return and retain columnstore index information, the returned results will be zeros so there isn’t much value unfortunately.
SELECT * FROM sys.dm_db_index_operational_stats(DB_ID(), OBJECT_ID('dbo.FactInternetSales_VLT'), NULL, NULL);
Partition number here may be of some use, but it would be more helpful to go to sys.column_store_dictionaries such as the following through sys.partitions and onto the segments and dictionaries catalog views.
Summary
Although the columnstore index documentation is still building and the community is also building on this with articles and blogs based on all the findings that occur daily, there is a foundation of documentation that can be helpful in working with columnstore indexes. As columnstore indexing evolves, more management objects and unearthing of the metadata and xVelocity technology will surely be shown so we can better utilize this method of indexing. As they are, the enhanced performance columnstore indexing can give us is, undeniably, invaluable in a world where data is growing rapidly.


