


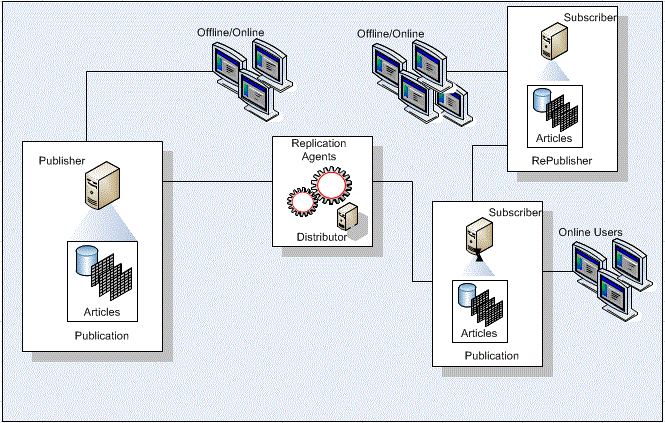
Does this kind of diagram get you excited about what’s next to come in designing and maintaining a system that involves online and offline data consuming users? If it does, read on…

One of the cool things about SQL Saturday events, they don’t necessarily need to be on a Saturday. The annual Minnesota SQL Saturday is a perfect example. They hold theirs on a Friday. From my understanding, this is to be more adaptive to the schedules of the community there. Although it may sound odd to have a SQL Saturday on a Friday, I can easily see why a company would see value and grab their attention more when a training event like SQL Saturday is during a normal business day. If you need proof in this method of organization, the Minnesota SQL Saturday last year was a great success. This year, registration is already to the capacity of the venue and the waiting list has been initiated.
Last year I was unable to attend or speak but this year I’m extremely excited to announce that one of my sessions, Merge Replication for Offline Data Mobility, has been selected.
A full description of this session
Merge Replication for Offline Data Mobility
How many times have you been sitting in a meeting and you hear, “We want all our users to have access to the data, 24/7. That includes when they are offline and on a client location”. At this point you may start letting out a large sigh because you are thinking, “How could the user get to the data if there is no connection?” This isn’t as hard as you may think and this session will show how to use SQL Servers Merge Replication in order to accomplish the task. Merge replication offers a scalable option for data mobility. This session will go over how Merge Replication can be used to replicate data to users that spend many hours offline.
Data mobility is an important part of any application. Replication holds great value in making this happen along with having a unique ability for many areas of performance enhancing power with it. During the session, I’m going to go over a typical setup that any size company and application can use to achieve this goal. At this point, if you are a developer, you may be saying the session wouldn’t be very useful for you. I think it would hold great value however, even for developers. Knowing how the data is getting there, time it takes to be there, developing against potential problems that replication events can make happen and simply knowing what you need or don’t for offline development can be key to success. I may even go over a little Sync Framework just to spark your developer curiosity and meet you on a programming level 🙂
I hope to see everyone in Minnesota! This is going to be a truly great event.


