


This is your query on a rollercoaster. Not a fun trip and sometimes bringing a paper bag with you is a necessity.

It really happens
The scenario starts with a phone call from the support desk reporting failed integrations from the ERP system to the WMS system. This integration process is critical for the production of items with the company to fulfill orders and build inventory. Without the process, finished goods inventory is not posted and thus does not become available for sale. This causes a more detrimental effect on financial reporting and filters down to the revolving reason we are in business – making money.
In a normal IT team structure, there are three high-level components we all start with to troubleshoot backend systems process failures: Network, Systems/Applications and Database Server Performance. Each team sector should work together and focus on their specialty to document possibly causes. This will benefit the situation the best and also create a collaboration point where the team can compile everything found in order to proceed with the fix. As a DBA you will find yourself in this situation often and there are a couple of key points you can focus on to quickly determine if the cause is the database server. After your findings the DBA can then focus on areas to alter, tune or repair.
In the scenario that my own team found themselves in recently, the troubleshooting steps lead to find timeouts occurring within the integration processing of the application. The application was kind enough to have built in logging to show the query that was being timed out which greatly lowered the analytical stage in finding the root cause. In most cases this isn’t logged but with the combination of profiler and monitoring during these timeouts, the query can be extracted in order to proceed with determining if it is the cause and possible resolution.
Once looking at the execution plan of the query that was in the log related to the timeouts, an RID Lookup operation was found with an Index Seek. In some cases an RID Lookup may not cause any problems with performance and go without notice. However is this case, the table in question that the query was requesting data from was roughly five millions rows. This type of table size will cause the RID Lookup to slow the performance of even the simplest queries.
Showing is learning
To portray the data, indexes and query we will step through recreating the exact situation that occurred.
First step will be to create a database that we can work in. We will then create an item table and load the item table from use of the AdventureWorks database table, “Production.Product”.
Note: AdventureWorks can be used for this entire recreation but to retain the database as it is the secondary database was created for example purposes.
Run the following to prepare the database and needed objects:
USE master
GO
CREATE DATABASE [EXE_PLANS] ON PRIMARY
(NAME = N'EXE_PLANS',
FILENAME = N'C:Program FilesMicrosoft SQL ServerMSSQL10.MSSQLSERVERMSSQLDATAEXE_PLANS.mdf',
SIZE = 2048KB,
MAXSIZE = 1024000KB,
FILEGROWTH = 409600KB)
LOG ON
(NAME = N'EXE_PLANS_log',
FILENAME = N'C:Program FilesMicrosoft SQL ServerMSSQL10.MSSQLSERVERMSSQLDATAEXE_PLANS_log.ldf',
SIZE = 1024KB,
MAXSIZE = 102400KB,
FILEGROWTH = 10240KB)
GO
USE [EXE_PLANS]
GO
CREATE TABLE ITEMS
(ITEMCODE INT,
ITEMNAME VARCHAR(50),
LASTMODIFY DATETIME,
CREATEDATE DATE,
CREATETIME TIME)
GO
INSERT INTO ITEMS
SELECT
Prods.ProductID,
Prods.[Name],
GETDATE(),
GETDATE(),
GETDATE()
FROM
AdventureWorks.Production.Product Prods
Now that we have our testing area, we can create some common indexes that may be found on a table like the items tables.
First a nonclustered index on the ITEMCODE
CREATE UNIQUE NONCLUSTERED INDEX IDX_ITEMID ON ITEMS
(ITEMCODE)
WITH (FILLFACTOR = 85)
GO
Next, a nonclustered index on CREATETIME, ITEMCODE and CREATEDATE
CREATE NONCLUSTERED INDEX IDX_PRODID_DATE_ASC ON ITEMS
(CREATETIME,ITEMCODE,CREATEDATE)
INCLUDE (ITEMNAME)
WITH (FILLFACTOR = 80)
GO
Once these indexes are created we can run a basic query to extract ITEMNAME and CREATETIME with a WHERE clause only looking at a specific ITEMCODE value.
SELECT
ITEMS.ITEMNAME,
ITEMS.CREATETIME
FROM ITEMS
WHERE ITEMCODE = 1
GO
We should be fine as the nonclustered index, “IDX_ITEMID” should be used in an index seek given the WHERE clause on ITEMCODE. However, when we run this query to check the estimated execution plan, we can see we have a lookup occurring.

The lookup is caused by the fact that there is not a covering index to fulfill the entire needs of the query. The WHERE clause and columns returned combined equate to, “covering”. In order to satisfy this query and remove the RID Lookup, we need to create a covering index or a clustered index on the ITEMCODE. Creating a clustered index physically orders the data under the conditions of the index and in some cases (like this) that was not possible. An effective solution in this case is a nonclustered index covering the entire query requirements.
Note: Let’s say that the table in question isn’t a HEAP and there is an existing clustered index on a different key. Since we can only have one clustered index per table, the resolution of ITEMCODE becoming a clustered index to resolve our RID Lookup is not possible. A nonclustered index is then the only way to resolve (or remove) the RID Lookup.
To create a covering index we can do the following
CREATE NONCLUSTERED INDEX IDX_COVERING_ASC ON ITEMS
(ITEMCODE,LASTMODIFY,ITEMNAME,CREATETIME)
WITH (FILLFACTOR=80)
GO
After looking at our execution plan, we should see only the index seek operation being performed

Let’s put things into perspective. We all know an index seek is optimal (in most cases). We do see our index seek in the execution plan prior to our resolution of a covering index but we have the handicap of the RID Lookup being performed in a nested loop with the index seek. This will result in the cost of the index seek operation plus essentially the same effect of a table scan under a nested loop operation. For each record we find in the index seek, we have to run out to the disk, find the remaining data we need in order to fulfill the needs of the query.
This is all reflected in a nested loop operation.
What is shown below is the Index Seek retrieving the data directly based on the index pointers and requiring a need to loop back to the data to fulfill all of the data needed by the request. This causes the query to perform slowly and also increases the possibility for high CPU utilization and high IO.
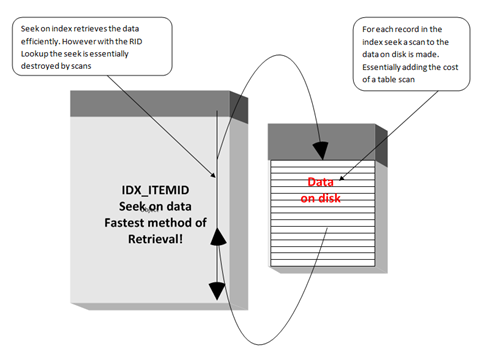
Basic troubleshooting steps of query performance like this should be a daily part of database tuning and monitoring. Allowing changes to go directly into production database servers without the initiative of code reviews and heavy testing will allow these types of problems to happen. The best resolution of all is to prevent these types of problems by not bypassing those normal transport objectives.

For learning more on Execution Plans, I highly recommend purchasing, SQL Server Execution Plans by Grant Fritchey. This book goes into each operation you will encounter in plans and some ways to resolve operations that are not optimal. Grant (Twitter | Blog) is also a widely known and respected expert on Execution Plans and database tuning. Reading his blog and following him will greatly benefit your daily work as a DBA or Developer on SQL Server.


