


Merge Replication can be a powerful tool for data mobility and distribution. Data can be distributed across a wide geographical range and maintained either from a client online or offline, and receive data changes from one or many sources on demand. With any large geographical distance, the least amount of data distributed per subscriber is ideal. If the source or originating data is in the hundreds of gigabytes, sending the entire database is simply not feasible. What can be more applicable is to send the data that is specific to the unique or multiple subscribers in order to accomplish the business need required by the subscribers.
Merge Replication offers data partitions, or a subset of data based on a system function HOST_NAME() or SUSER_SNAME() as a parameter to be used as a predicate in the query used to select the subset of data. This is referred to as a parameterized filter. These filters are applied at the row level in tables and can be reviewed as a simple SELECT statement.
For instance, if we altered the table Person.Person in the database AdventureWorks to support of Merge Replication, we would add a column named, LoginAccount. This new column would hold user domain accounts (DOMAINusername). A parameterized filter on this column could then be setup to evaluate each row that matches an SUSER_SNAME() passed in by the connecting domain user. When this occurs, we can compare this with a T-SQL SELECT statement as shown below
SELECT * FROM Person.Person WHERE [LoginAccount] = SUSER_SNAME()
With the column addition made to Person.Person, a publication could be set up to use the SUSER_SNAME() as a parameterized filter on Person.Person. This would be done in the setup by adding a filter to the table Person.Person and adding a WHERE LoginAccount = SUSER_SNAME()
SELECT <published_columns> FROM [Person].[Person] WHERE [LoginAccount] = SUSER_SNAME()
This configuration in the publication will automatically or manually force a data partition to be generated for any valid domain user with a listing in the publication access list when they initially connect to the publication. For example, a publication that is based on Person.Person with a filter on SUSER_SNAME() and setting of “A row from this table will go to only one subscription” would reveal the Data Partitions page in the publications properties. Note: Selecting either one or multiple subscriptions availability for partitions will be discussed later. The data partitions page shows all data partitions that have been created manually or by a subscriber that has connected to the publication.
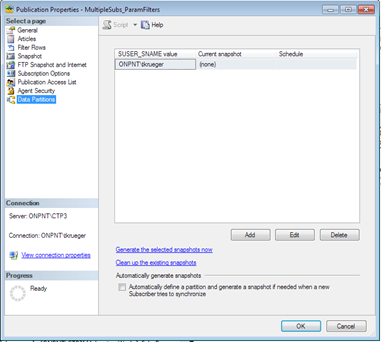
Given this configuration and a subscription connecting to the publication initially, a data partition snapshot will be generated and applied to the subscriber. During the evaluation process, replication will use data partition views to retain the statement that we went over earlier. This statement is how the evaluation process will be performed. These views are a key object that can be used to assist in performance tuning merge replication with parameterized filters. This is even more valuable in tuning when Join Filters are introduced into the solution, and filtering becomes complex and starts to severely impact performance.
Each data partition view is created and can be viewed under the System Views listing in SSMS, or by reviewing the sys.views catalog view for views following the naming convention of
MSmerge_{publication name}_{article}_[ | PARTITION]_VIEW
To view the definition of a data partition view, use sp_helptext. The Person data partition view would be reviewed with the following statement.
sp_helptext ‘dbo.MSmerge_MultipleSubs_ParamFilters_Person_PARTITION_VIEW’
The definition of this view
create view dbo.[MSmerge_MultipleSubs_ParamFilters_Person_PARTITION_VIEW]
as
select [Person].[rowguid], [Person].[LoginAccount], msp.partition_id from [Person].[Person] [Person] , dbo.MSmerge_partition_groups msp where (msp.publication_number = 5 and ( (
([LoginAccount] = msp.[SUSER_SNAME_FN] )) )) and ({fn ISPALUSER('6ED96157-62B5-4802-9555-2F6E3662C069')} = 1 or (HAS_PERMS_BY_NAME('[Person].[Person]', 'OBJECT', 'SELECT')
| HAS_PERMS_BY_NAME('[Person].[Person]', 'OBJECT', 'UPDATE')
| HAS_PERMS_BY_NAME('[Person].[Person]', 'OBJECT', 'INSERT')
| HAS_PERMS_BY_NAME('[Person].[Person]', 'OBJECT', 'DELETE'))=1)
The performance of this view is critical to the replication process and evaluation of the data partitions. This view generated the following plan on a development system.
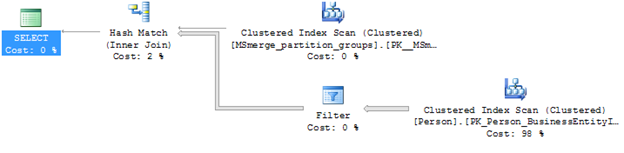
IO Statistics of this statement
Table ‘Person’. Scan count 1, logical reads 3816, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘MSmerge_partition_groups’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
This plan is not very optimal and could benefit greatly from the creation of two indexes; one index on MSmerge_partition_groups and another on Person.Person. Person.Person is the table with the heavy logical reads due to size on the development database. With replication of this type, even with small row count sampling, it is highly recommend planning ahead for this type of indexing. Replication system tables grow quickly and can cause unwanted problems with replication and other connections to the database if not tuned prior to deployment. Tune for the largest row sample size and prepare for the largest. This will ensure you are capable of scaling the data and replication process in an uninterrupted manner to the users.
Person.Person would be indexed on LoginAccount from the predicate and then include the handle the join criteria to the MSmerge_partition_groups.
CREATE NONCLUSTERED INDEX [IDX_PARTITION_LOGIN_GUID_ASC]
ON [Person].[Person] ([LoginAccount])
INCLUDE ([rowguid])
GO
Creating this index alone will improve our performance by an estimated 80%, as tested in development. To improve further, and prepare for growth, the following index should be created on MSmerge_partition_groups as well.
CREATE NONCLUSTERED INDEX [IDX_PARTITION_EVAL_ASC]
ON dbo.MSmerge_partition_groups ([publication_number])
INCLUDE ([SUSER_SNAME_FN],[partition_id])
GO
The new optimized plan

What’s next?
We’ve gone over parameterized filters with merge replication and also a key performance tuning aspect with the data partition views in this. Furthering the topic, next we will discuss join filters and the added need for performance tuning and design considerations. Data partitions and merge replication offer an enhanced ability to distribute data in a set base designed for specific subscriptions and users. This ability allows for devices and slower connection speeds access to data, options to alter that data or insert new data and synchronize to sources. In business, this can open several development possibilities and creating an overall more efficient process and in turn, revenue builder.


