


This is day sixteen of the SQL Advent 2012 series of blog posts. Today we are going to look at the lack of database design and normalization. Normalization and database design is a big enough topic that there are 500 page plus books written about it. This post will barely scratch the surface, if you want to know more about this topic pick up a book about it. Pro SQL Server 2008 Relational Database Design and Implementation is one that I recommend. I did an interview with the author here: Interview With Louis Davidson Author of Pro SQL Server 2008 Relational Database Design and Implementation
Normalize until it hurts, denormalize until it works
So what is normalization? Normalization is the process of organizing the columns and tables of a relational database to minimize redundancy and dependency. Normalization usually involves dividing large tables into smaller (and less redundant) tables and defining relationships between them. The objective is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
Let’s take a look at a simple example. Let’s say we have a book store and we want to capture the book title, the date the book was published as well as the author. We are keeping this very simple so no ISBN or publisher or any additional information.
You might come up with a table like this right?
CREATE TABLE Books (BookdId int, Title varchar(100), PublishDate datetime, Author varchar(100))
GO
One of the problems is that if an author wrote more than one book, the author will be stored in that table more than once. What it the authot is a woman and she gets married and decided to change her name, how will you know this is the same person?
Let’s drop that table since we are going to recreate it
DROP TABLE Books
GO
Now, let’s create two tables, we are going to create an Author table and a Books table. The Author table will hold the AuthotID, the last name as well as the first name. Now we can use the AuthorID and store that in the Books table
Create Table Authors (AuthorID int, FirstName varchar(100), LastName varchar(100))
GO
CREATE TABLE Books (BookdId int, Title varchar(100), PublishDate datetime, AuthorID int)
GO
So what is the problem with this so called design? Ever heard of a book that had more than one author? Of course you have there are many of those, this is especially true with technical books.
Let’s drop those tables since we are going to recreate it.
DROP TABLE Books, Authors
GO
Now what we have to add is a third table, this table will have just two columns, the BookID and the AuthorID, now you can handle many authors per book without a problem. The AuthorID column will now be eliminated from the Books table as well.
Create Table Authors (AuthorID int, FirstName varchar(100), LastName varchar(100))
GO
CREATE TABLE Books (BookdId int, Title varchar(100), PublishDate datetime)
GO
CREATE TABLE BookAuthors(BookdId int,AuthorID int)
GO
What else are we missing? How about some primary keys and foreign keys. We are going to make BookID and AuthorID a primary key. Those two columns will also be a foreign key in the BookAuthors tables. Since an author can’t write the same book twice, we will also make the combination of BookID and AuthorID a primary key in the BookAuthors table
Here is what you will end up with
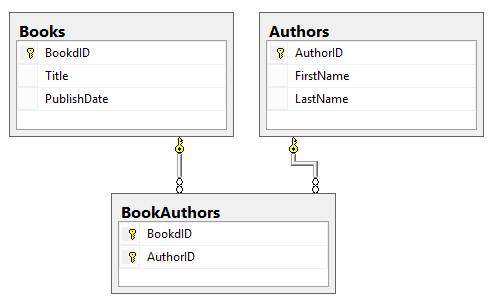
Now, here is the code to add the primary keys and foreign keys to the table
ALTER TABLE dbo.Books ADD CONSTRAINT
PK_Books PRIMARY KEY CLUSTERED
(BookdID) ON [PRIMARY]
GO
ALTER TABLE dbo.BookAuthors ADD CONSTRAINT
PK_BookAuthors PRIMARY KEY CLUSTERED
(BookdID,AuthorID) ON [PRIMARY]
GO
ALTER TABLE dbo.Authors ADD CONSTRAINT
PK_Authors PRIMARY KEY CLUSTERED
(AuthorID) ON [PRIMARY]
ALTER TABLE [dbo].[BookAuthors] WITH CHECK ADD CONSTRAINT [FK_BookAuthors_Authors] FOREIGN KEY([AuthorID])
REFERENCES [dbo].[Authors] ([AuthorID])
GO
ALTER TABLE [dbo].[BookAuthors] CHECK CONSTRAINT [FK_BookAuthors_Authors]
GO
ALTER TABLE [dbo].[BookAuthors] WITH CHECK ADD CONSTRAINT [FK_BookAuthors_Books] FOREIGN KEY([BookdID])
REFERENCES [dbo].[Books] ([BookdID])
GO
ALTER TABLE [dbo].[BookAuthors] CHECK CONSTRAINT [FK_BookAuthors_Books]
GO
That is a lot of code, this is where modeling tools come in handy. You can use the diagramming tool in SQL Server Management Studio but it is not full feature like the ones below.
SAP (Sybase) PowerDesigner
Embarcadero ER/Studio
IBM Rational Systems Architect
Dell Quest TOAD
I have used ERwin and Visio in the past but use PowerDesigner these days.
Now how would you handle the name change for the author? You can introduce another table where you would have first and last name together with start and end dates, this now enables you to still have the author being one author for reporting purposes but you can now still represent the name correctly for a specific point in time. Another example of this would be the stock market, companies will change the ticker, Sun Microsystem change the ticker from SUNW to JAVA, sometimes they change the name as well, Apple dropped Computers from the name. You still want this to be the same company so you won’t just add another row otherwise how would you do historical charting?
This is also why I like keys that don’t have meaning, these are called surrogate keys, now when you change everything in the row it doesn’t matter. I once worked with a system where…are you ready for this……the primary key was the social security number, this key was then also used as a foreign key in another ten tables. Of course some people would be reluctant to give their real social security number, they made up a number. Now the person with the real number signed up and couldn’t he would call customer support, they would track down the person with the fake number and now the SSN had to be changed in over 10 tables, since we didn’t have cascade update turned on, this had to be handled manually (and of course make sure to highlight the WHERE clause otherwise you are toast)
Remember how we had that BookAuthors junction/lookup table? Sometimes you will actually see a comma delimited list of IDs in a varchar column. This is not the way to store more than one author for a book. This looks easier from an application point of view (however I disagree even here) but now you have to write some kind of row to column user defined function if you want to show all authors. Performance is also going to be a dud, an index can’t be used since your WHERE clause is not sargable.
Unnormalized database
This is a database which was never normalized to begin with
Denormalized database
A denormalized database is a database that was normalized but some parts have been denormalized for performance or maintenance reasons
For you to research/lookup
Keys
There are many types of keys, some of them are just synonyms, here are some of them: Candidate Key, Surrogate Key, Superkey, Natural Key, Alternate Key, Compound Key
Normal form
Like I said at the beginning of the post there many more things to this topic than covered here. I did not talk about normal form at all, make sure that you research what all of these mean
1NF First normal form
2NF Second normal form
3NF Third normal form
EKNF Elementary Key Normal Form
BCNF Boyce–Codd normal form
4NF Fourth normal form
5NF Fifth normal form
DKNF Domain/key normal form
6NF Sixth normal form
That is all for day sixteen of the SQL Advent 2012 series, come back tomorrow for the next one, you can also check out all the posts from last year here: SQL Advent 2011 Recap
 Denis has been working with SQL Server since version 6.5. Although he worked as an ASP/JSP/ColdFusion developer before the dot com bust, he has been working exclusively as a database developer/architect since 2002. In addition to English, Denis is also fluent in Croatian and Dutch, but he can curse in many other languages and dialects (just ask the SQL optimizer) He lives in Princeton, NJ with his wife and three kids.
Denis has been working with SQL Server since version 6.5. Although he worked as an ASP/JSP/ColdFusion developer before the dot com bust, he has been working exclusively as a database developer/architect since 2002. In addition to English, Denis is also fluent in Croatian and Dutch, but he can curse in many other languages and dialects (just ask the SQL optimizer) He lives in Princeton, NJ with his wife and three kids.
