


Recently I was talking to some friends about alerting on complex streaming data. Between some past event processing work we had done and earlier experience aggregating real-time manufacturing data, I was thinking a lot about projecting and evaluating results as we go versus querying the for results on some frequency. It seemed like a realistic approach and I couldn’t stop thinking about it, so I decided to prototype the pieces that I was least familiar with.
The idea is based on one that is used frequently in CQRS and I’m far from the first to have it, professional tools like Apache Spark and Amazon Kinesis Data Analytics support this idea of a continuous query over time, but part of the driver was also the desire to support user-defined rules in a multi-tenant environment and see how that would impact my design thinking as I prototyped.
It pushed me to learn some new (to me) things, so I thought I would share what I did and perhaps some of this will be helpful or interesting to others as well.
Just Enough Prototyping w/ Lambdas, Kinesis, and DynamoDB
So I set out to build just enough of a prototype to answer the unknowns, creating a small serverless application that receives a stream of events for 2 clients that each have 5 machines that change state simultaneously (warming up, running, shut down) so I could experiment with rules with different criteria and get a feel for how complex this would be.
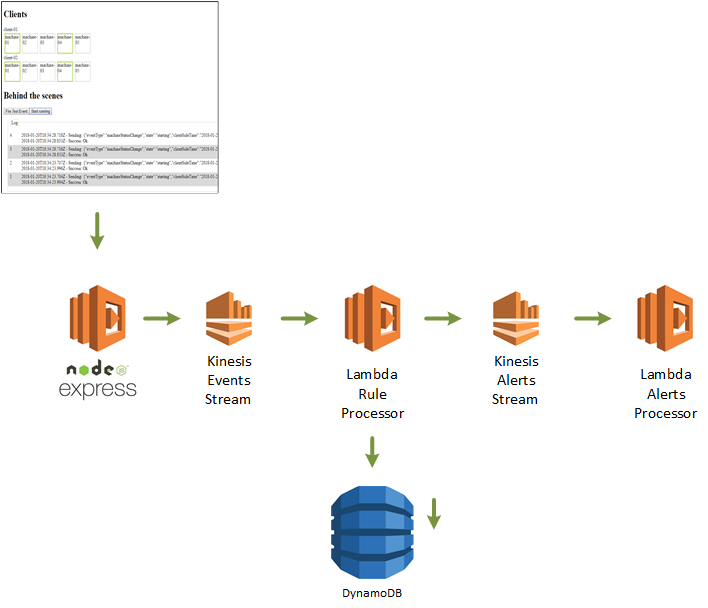
Analytics Overview
I would use a fake front-end to manage some fake "machines" for 2 "clients", that would change state occasionally and publish those events. The fake site would push those events into the beginning of my real prototype, an Amazon Kinesis stream for events. An AWS Lambda function, the "Rule Processor", would be triggered by a batch of events on the stream. It would load the appropriate rules out of DynamoDB for each client, evaluate which rules each event applies to, then combine that with previously cached events from DynamoDB and evaluate whether the rule is satisfied. If so, an alert would be published to the Kinesis Alerts Stream. Further downstream, an "Alerts Processor" function would receive those alerts and, in a real system, decide what types of notifications were necessary.
Rules and DynamoDB Store
The buckets of data in AWS can be thought of as query results that I am constantly updating for each event that comes in.
Example Event:
{
"eventType": "machineStatusChange",
"state": "stopped",
"clientId": "client-01",
"machineId": "machine-01"
}
Example Rule:
// alert when all machines enter stopping state
new Rule({
ruleId: 'hardcoded-rule-02',
clientId: "client-01",
where: [{ 'property': 'machineId', 'equals': '*' }],
partitionBy: ['machineId'],
evaluate: {
type: 'all',
having: {
calc: 'latest',
property: 'state',
equals: 'stopped'
}
}
})
I wouldn't expect an end user to enter a rule like this and would probably rework the structure if this was intended to be a real system, but it is good enough to let me resolve the bigger unknowns around processing events and partitioning data.
Implementation
I used the serverless platform to define and build these functions, running locally with a combination of serverless-offline, kinesalite, dynalite and some tooling I cooked up to run kinesis functions locally (see Serverless HTTP + Kinesis Lambdas with Offline Development). I also used wallaby.js heavily to give me fast, inline feedback with unit tests inside larger iterations of manual testing with the express front-end I bolted into another HTTP Lambda.
The code can be found here: github: tarwn/serverless-eventing-analytics
The core of the system is the "Rule Processor":
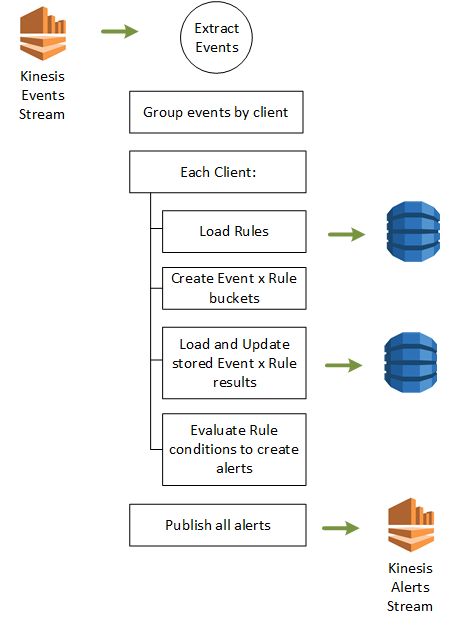
Rule Processor Logic
The Rule Processor is triggered by a batch of events from Kinesis:
- Extract the event data from the batch
- Group them by Client
- For Each Client's group of events:
- Load the client's rules
- Create result buckets for each rule and add applicable events to it
- Load past result data from DynamoDB and append local result data
- Evaluate rule conditions and output any alerts
- Publish the collected alerts to the Alerts Kinesis Stream
Each of the "Event x Rule" result buckets can be thought of as the results of a query we're running continuously as events flow in (which is about the time I realized I was duplicating work a bunch of much smarter folks had put into stream analytics packages above). So if I have 6 rules that care about machine events and 1 event comes in for "machineStatusChange" on "machine-01", then I'll add that event to all 6 buckets individually (storage is cheap).
The rules are responsible for generating their own unique result name, which by convention is {clientId}/rules/{rule id}/{where clause specific bits}. You can see more in /functions/ruleProcessor/lib/rule.js .
The function code is a slightly messier version of the steps above:
/functions/ruleProcessor/handler.js (github)
module.exports.streamProcessor = (kinesisEvent, context, callback) => {
const events = helper.extractEventsFromKinesisEvent(kinesisEvent);
const eventGroups = helper.groupEventsByClient(events);
Promise.all(eventGroups.map((group) => evaluateAndStore(group)))
// ...
.then((nestedAlerts) => {
var alerts = flatten(nestedAlerts);
const publishAlerts = alerts.map((alert) => {
return publishAlert(alert);
});
return Promise.all(publishAlerts);
})
// ...
};
function evaluateAndStore(eventGroup){
const clientRules = rules.get(eventGroup.clientId);
const localResults = helper.applyRules(clientRules, eventGroup);
// open per-rule results to merge with stored results and evaluate for alert
return Promise.all(localResults.map((result) => {
const appliedRule = clientRules.find((cr) => cr.ruleId = result.ruleId);
return results.applyLocalResultToStoredResult(result, appliedRule)
.then((completeResult) => {
if (appliedRule.meetsConditionsFor(completeResult)) {
console.log(`ALERTED for ${completeResult.uniqueResultKey}`);
return appliedRule.getAlertFor(completeResult);
}
else{
console.log(`No alerts for ${completeResult.uniqueResultKey}`);
return null;
}
});
}))
.then((nestedAlerts) => flatten(nestedAlerts));
}
<p>
When events start flowing through, we can see data getting loaded and applied for each of those rules. Client-02 alerts when any machine enters a stopped state (as opposed to all machines, like client-01 above), so we can see
</p>
<div id="attachment_8902" style="width: 837px" class="wp-caption aligncenter">
<img src="https://lessthandot.z19.web.core.windows.net/wp-content/uploads/2018/01/RuleProcessorOutput.png" alt="Rule Processor Output" width="827" height="255" class="size-full wp-image-8902" srcset="https://lessthandot.z19.web.core.windows.net/wp-content/uploads/2018/01/RuleProcessorOutput.png 827w, https://lessthandot.z19.web.core.windows.net/wp-content/uploads/2018/01/RuleProcessorOutput-300x93.png 300w, https://lessthandot.z19.web.core.windows.net/wp-content/uploads/2018/01/RuleProcessorOutput-768x237.png 768w" sizes="(max-width: 827px) 100vw, 827px" />
<p class="wp-caption-text">
Rule Processor Output
</p>
</div>
<p>
You can run this yourself by cloning the <a href="https://github.com/tarwn/serverless-eventing-analytics">github repo</a>, running <code>npm run offline</code>, and then opening your browser to <a href="http://localhost:3000">http://localhost:3000</a>.
</p>
<h2>
Next Steps
</h2>
<p>
This proved out the big question I had, and maybe helped some folks with running Kinesis functions locally (previous post), so I'm calling it a win. If I were building this for production, the next steps would be to continue making the rules richer, figure out how to age data out of the result set I'm storing in DynamoDB, and start building an interface that would allow you to create and store a rule on your own. Another big question would be whether I also need some sort of regular event (second? Minute) to re-evaluate rules for data to fall off or for queries that want to rely on the continued state of a value without needing new events to come in and restart it (the machine is still running, still running, still running...).
</p>
 My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.
My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.

