


LessThanDot is composed of 3 distinct PHP packages wired together with some home-built screens, a homemade authentication system, and a bit of string and glue. In fact, it is similar to hundreds of thousands of systems out there, that evolve out of bits and pieces integrated in unique and interesting ways.
We deploy our site manually using file copy methods, with separate QA and Development environments. Fortunately, being PHP and not compiled, we can limit our deployments to just changed files instead of full deployments. Unfortunately the closest (Dev and Prod) have over 80 file differences, and our code repository has over 1000 (yes, one thousand) from production. We’ve accidentally deployed older versions of files from our code repository. We’ve even deployed the QA or a local Dev configuration file to production, which doesn’t work so well.
As I said, this is a great example for hundreds of systems out there.
Who is at fault?
I’ve been on a few projects in the past that had similar problems. We operated in one of two modes, super extremely careful or push-and-pray. Both cases depend on after hours deployments and take the fragility of the deployment process as a given. We accept and live with the fact that builds are dangerous and assume danger is inherent to all build processes. In the poorer cases, we actually “blamestormed”, trying to determine who was to blame when a build went wrong.
The problem wasn’t the inherent complexity of builds or even a specific individual, but the process we were using to do those deployments.
Every build and deployment was a uniquely baked occurrence. We would follow a couple memorized steps and then fill any holes as we noticed them, running additional tools or steps as needed. Each was a unique snowflake, often created through steps followed in a somewhat random order. We didn’t have time to build or automate a process because builds were too complex, took too long, or required human ingenuity and creativity.
Basically, we were victims of ourselves.
Which brings us back to the LessThanDot site.
Whats in a Deployment
Recently I posted a series on a personal continuous delivery project. Near the end, the LTD site suffered a several hour outage. We have backups, but it still got me thinking about how hard it would be to recover or re-deploy our site. The continuous delivery project I was working on may have been a smaller site, but it deployment process was actually far more complex than what we needed for the LessThanDot site. And it was actually easier than our manual LTD process. Hmm.
What was making our LessThanDot deployment process tricky was not the number of steps or size of the site, it was the fact that we were counting on human beings to do something in a repeatable fashion without even so much as a checklist.
And somewhere a computer is laughing at us.
We basically played to our human weaknesses, when all along we should have been taking advantage of the one thing computers do really, really well: follow instructions in a repeatable fashion.
A good, automated build and deployment process would not only do everything consistently, but it would force us to address some issues with our source code repository and configuration management. We would be forced to keep the sites in sync with one another, manage changes that we wanted to deploy through the Dev/QA/Prod process, and reduce the amount of time that the site was running in a bad state as files individually uploaded and replaced their older counterparts.
The New Process
The new process is not very complex.
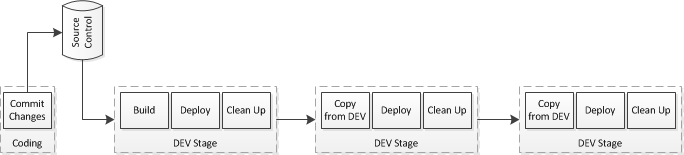
This should say DEV Stage, QA Stage, PROD Stage – Human Copy/Paste Error Strikes Again
As changes are committed into our source code repository, they are picked up and run through the DEV step. The build does a small amount of work, then deploys them. When we are ready, we push a button to run the QA step, which picks up the last set of files processed by DEV and deploys them to a folder in the QA environment. Same thing for the production step.
All of the deployments work the same, with the only difference being the environment name and path. This flushes out any issues in our deployment scripts before they threaten production.
Simplified Process:
- Create a new (environment)/(datestamp) folder
- Deploy the entire site to that new folder
- Deploy the correct site configuration for the environment
- Update the symlink (environment)/current to point at this new folder
- Delete any deployed sites that aren’t the current or previous site (ex, the previous-previous one)
Apache is pointed at that symlink folder, so flipping it to point at the new folder redirects all traffic (over the course of about a minute) to the new site. We keep the previous version handy to help that transition and to provide a fallback plan if we really, really break the site. Copying the environment-specific configuration file in forces us to keep our code environment-agnostic (which it already was) but also simplifies configuration management because we know exactly how it is going to work every time. And in the real, slightly more complex version of the process we actually have moved the environment-specific media, upload, and cache folders to non-versioned areas so they are not impacted by our versioning system or method of flipping symlinks to deploy.
Getting here required a number of fixes, but we are in a better place and have a foundation for further improvement.
Why it Matters
What’s important is that our site is representative of a lot of systems out there. Often the pain of deployments or builds is actually far stronger when it’s done manually because we are already aware of how painful the process is and some of the problems we would have to overcome to automate it. The end result, though, is the freedom to deploy more frequently and in a far safer and more consistent manner than we ever enjoyed in the past.
Deployment is basically question-free now. We didn’t wait to try and build an all-inclusive process that would solve all the problems we could think of, in fact I can think of several painful ones still waiting for us. We solved some of our critical pain points and have a foundation for further improvements. And what the heck, I just deployed to production again because I felt like it.
 My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.
My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.


