


Welcome to our second class for HA and DR week of SQL University. Yesterday we went through defining HA and DR along with some common practices you can use. Today we are going to focus on the concept, “Backups are for sissies!” OK, we’re really going to look at backup and restore for Disaster / Recovery (DR) and how being a sissy and always backing up our databases and testing out restores is a proven strategy for DR.
When all else fails and the walls are falling down on the database servers, backups will be your life preserver. Backups are the foundation for Disaster and Recovery (DR). Backups can also save you when high Availability (HA) completely fails you. Let’s get started!
Define a backup
A full database backup contains a full representation of the database with enough of the transaction log in order to recover everything when a restore is performed. In SQL Server, we have several types of backups to help with various configurations and sizes of our databases.
Full Backup – Defined above as a full representation of the entire database and enough of the log to recover the point in which the backup was executed
Differential Backup – Differential backups add benefits to backup strategies by giving you a quicker recovery path. These backups contain the changes between the previous full backup and when the differential was executed. If you are recovering from a disaster and have a database in Full Recovery Model with transaction log backups, you are not required to restore the base, the differentials, and all the transaction log backups. Only the base and the differential are required to bring you to the point in time of the differential backup.
Transaction Log Backup – This type of backup contains the transactions since the last backup. This only applies to databases in Full or Bulk-Logged Recovery Model. For recovery to point-in-time, transaction log backups are needed, as well as required when in Full recovery to maintain the log files. By default, the Model database is set to Full recovery model which dictates how new databases are created. This means that any database you create without specifying default properties will adopt the Model’s recovery model. A common practice is to alter the Model database and set the recovery model to Simple. This will prevent out-of-control log growth when these types of backups are not put in place.
Partial Backup – Partial backups are primarily used when all you want is in the primary filegroup of a database. This leaves all the other filegroups out of the backup and reduces the size of the overall backup file.
File backups – File backups help with large databases and recovering only portions of the database. They are exactly what they are named: a method for backing up a file or filegroup in a SQL Server database. Given that some databases exceed the Terabyte size, a File backup can be very useful in protecting critical tables as one chunk in a File backup. They also can be used in ETL operations for a quick backup strategy and rollback point while not needing to recover an entire database if corruption occurs.
Last Resort Recovery
While taking backups into consideration in DR strategies, there is one primary goal: get them offsite. Database backups will not help a DBA recover if they are located on the same systems and in the same location as the primary databases. In order for backups to become a DR strategy, we need to get them offsite. This can include another location that only has one server powering a disk array, or a complete mirror of the data center itself. The backups will not help us if
- They are not run
- They are in the same site as the disaster
Although backups are the foundation of DR, they are a slow method of restoring the databases. For Terabyte databases, a backup and restore can take several hours. This downtime is money lost. Given the restore times, backups should complement DR with all the other strategies put in place to recover. Backups are the almighty in terms recovering when all else fails.
Location of backups
The location of the backups is important in order to make them helpful in DR. The backups will always be required to be offsite from the primary locations, without exception. This includes all of the sites and their own unique databases. This means that each location can become a DR site for others for retaining the backup files offsite.

In the diagram above, database servers A and B on Site 1 rely on the offsite backups on Site 2 for recovery. Site 2, however, has a local application and database server C that is unique to the facility. Having this database exist at Site 1 would be not utilizing resources well and could cause performance problems for the application in Site 2. In order to bring server C into the DR strategy, the database backups are sent offsite to Site 1.
Getting backups offsite can consist of a few methods.
- Backup to tape and physically ship them offsite
- Backup to repositories and move them on designated network lines or off hours
- Backup directly to the offsite via UNC paths
Backing up to tape has been a common practice since the mainframe heydays. It is cost effective and with newer tape abilities, multi-Terabyte single tapes can hold and retain data with expected shelf life of 50 to 100 years. LTO truly has come a long way.
Getting our backup file with BACKUP
The BACKUP DATABASE statement can be daunting at first glance so can the SSMS wizard and options.
Example: Create a database DBA and we will run a full backup on it
CREATE DATABASE TEST_DR_BACKUP
GO
ALTER DATABASE TEST_DR_BACKUP SET RECOVERY FULL
GO
Now that we have a database to backup, let’s execute a typical full backup statement
BACKUP DATABASE TEST_DR_BACKUP
TO DISK = N'C:TEST_DR_BACKUP.BAK'
GO
This gives us a backup file in the C drive of TEST_DR_BACKUP.BAK. The backup contains everything we need to recover the database as is. If you notice, this backup statement was pretty quick. If we add CHECKSUM and the COPY_ONLY option to this statement, the execution time will be slightly longer.
BACKUP DATABASE TEST_DR_BACKUP
TO DISK = N'C:TEST_DR_BACKUP.BAK'
WITH CHECKSUM,COPY_ONLY
GO
Looking into the statement, we have several options to make our backups, “smart”. One method that is extremely useful in DR is the COPY_ONLY option. By using the COPY_ONLY option, we can create full backups of a database without affecting the LSN order in other backup strategies. This is a powerful option given the need to get backups offsite while we are using backup strategies locally for other things.
Crude but effective copy methods with batch files, .NET development and even manual efforts can also be used for moving the existing backup files. Automating these tasks is always a key operation to put into place. Backup/Restore operations take time and the time of a DBA is expensive when you consider all the tasks we need to cover in our day-to-day operations. Later, we will go over a proven automated strategy and feature in SQL Server.
Actually making a backup
Running backups can be as simple or complex as you want it to be. In order to accomplish backup/restore as a recovery method, all that is needed is disk space or tape resources. In some cases a lot of disk space will be required, but compression can bring the cost of these requirements down to a level that is much more manageable.
We also have options that can assist in preventing future problems by allowing DBAs to be proactive. CHECKSUM option is one extremely useful option but has its own overhead on the backup executions. CHECKSUM will allow you to detect media issues while performing the backup. This will completely verify each page and detect if the page is torn. Using CHECKSUM alone will cause the backup to fail and log an error of the media problems. In order to prevent the error from stopping the backup operation, we can use the CONTINUE_AFTER_ERROR option. This would allow the DBA to attempt a restore of the database to further detect the extent of the page errors along with compile a strategy for repairing them in the originating database.
The second statement that can be used is the RESTORE VERIFYONLY statement. This can be done after the backup has run completely, and will verify the page checksums without actually restoring the database itself. It is important to understand that this is useful information but not a replacement for a complete restore test.
Example: We have a Full backup located at C:sql_full_backupdbadba_full_20100606.bak
We could test this backup set by issuing the follow RESTORE VERIFYONLY statement
RESTORE VERIFYONLY
FROM DISK = N'C:sql_full_backupdbadba_full_20100606.bak'
GO
Resulting in the following information if errors are not found
The backup set on file 1 is valid.
In case of a torn page, the information would be written along with the page location. This would allow us to go farther into the problem and formulate the repair steps.
Restore is part of the backup
For backups in DR to be useful, we must test them by restoring them on a consistent schedule. Every backup has differences as does every database. Those differences are the state of the data and the state of the hardware when the backup was taken. Hardware problems can cause torn pages in a database and these issues will follow through to the backups. If a backup was completely successful and things like CHECKSUM (defined earlier) are not used to log errors, a backup can possibly fail to restore successfully and more importantly, become useless in a recovery plan. Best practice would be to restore every Full Backup and test the recovering levels of differentials and log backups in a Full Recovery model.
Automating these restore tests can help the process greatly. SQL Server Integration Services has the facilities to do this for you. Let’s look at a method with SSIS that can accomplish automating the restore process and reporting.
Note: large databases will add complexity and even inabilities to use these methods. File backups and other means that prevent automation will apply but should not forego testing by restoring.
Finding backups could be accomplished dynamically with expressions and variables. For example, the backup file naming convention could us YYYYMMDD designating the day the backup was run. A variable expression is used to find the specific file we want as
"C:\sql_full_backup\dba\dba_full_" +
(DT_STR, 4, 1252)DATEPART("yyyy", @[System::ContainerStartTime]) +
RIGHT("0" + (DT_STR, 2, 1252)DATEPART("mm", @[System::ContainerStartTime]), 2) +
RIGHT("0" + (DT_STR, 2, 1252)DATEPART("dd", @[System::ContainerStartTime]), 2) + ".bak"
This can then be added to a File System Task for Copy as the source (as well as used in destinations).
This package can then be run on the same day as the Full backup to find the correct file to perform our tasks on.
We can construct our package to perform the copy, restore the database and notify us of a successful restore or failures along the way. After this is completed, we can also run ALTER statements on the restore location in order to put it into a state it will not cause problems (i.e.: log growth) or run other application specific needs that may be part of our DR solution.
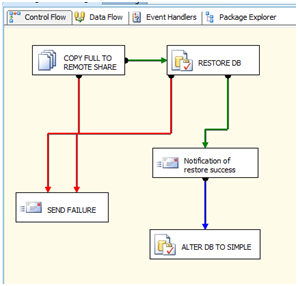
Running this process weekly (or on the Full backup day) can show problems that may otherwise not be found. This will prevent the day when the backups are called into action for recovery when all other DR strategies have failed.
Closing with homework to read and practice
Given the abilities in the features available, the tasks of having backups offsite for DR are simplified greatly. Backups are a cost effective and sound method for DR and HA recovery but only when tested out completely.
Make backups, make them often and test them by restoring them often. Lastly, get them offsite even if that means paying for the storage of tapes.
Going farther:
Paul Randal’s corrupt database for testing
Why did I link to Paul’s corrupt database? This is a valuable resource to test on. Through backup and restore and through all of this week of blogs, use this database to really see if you can recover using a DR or HA strategy.
If you liked this SQL University post, please take a moment to fill out the SQL University Course Evaluation and select HA/DR Week. Thank you!


