


Recently, during a pre-conference seminar that I presented, the group and I had a long discussion about why there would be a need to add a nonclustered index that consisted of the primary key as the key column. This topic also came up in a client training session I presented and in passing with a few peers. Given the topic and the overall consensus that this was a bad practice, I wanted to discuss it in a post and show a reason why creating a nonclustered index with a key column only being the primary key is actually a great optimization for some plans.
I’d like to focus on what would be the largest aspect to why you would use an index strategy of creating nonclustered indexes with only the primary key as the key columns: pages pulled into the buffer.
Let’s go through an example
Using AdventureWork2012, create a table from Sales.SalesOrderHeader that can be manipulated to fit the following tuning steps.
SELECT * INTO dbo.IndexPageCount FROM Sales.SalesOrderHeader
GO
ALTER TABLE dbo.IndexPageCount
ADD CONSTRAINT PK_SalesOrderID PRIMARY KEY (SalesOrderID)
GO
The above statement will create dbo.IndexPageCount and make the SalesOrderID the primary key column. At this point, no other indexing has been done. If a query was executed that relied on a predicate of the SalesOrderID, technically, further indexing may not be needed. For example, review the following query and execution plan generated from how the table and indexing is setup on IndexPageCount.
SET STATISTICS IO ON
SELECT
hdr.DueDate
,hdr.ShipDate
,SUM(SubTotal) AS SubTotals
FROM
dbo.IndexPageCount hdr
WHERE hdr.SalesOrderID < 50000
GROUP BY
hdr.DueDate
,hdr.ShipDate
IO results
Table ‘IndexPageCount’. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
And the plan generated from this query
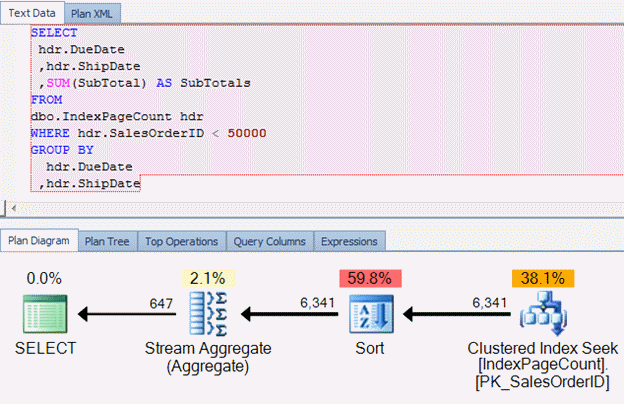
In all respects, this plan is optimized fairly well. The one key aspect to the query and plan is, the clustered index is the table and will pull all columns along with it, which equates to more pages that are required to come into the buffer. We can look at the page count required for the exact table by utilizing dm_os_buffer_descriptors, allocation_unit, sys.indexes and sys.partitions DMOs and catalog views.
Query referenced from: http://www.sqlteam.com/article/what-data-is-in-sql-server-memory
SELECT TOP 25
obj.[name],
i.[name],
i.[type_desc],
count(*)AS Buffered_Page_Count ,
count(*) * 8192 / (1024 * 1024) as Buffer_MB
FROM sys.dm_os_buffer_descriptors AS bd
INNER JOIN
(
SELECT object_name(object_id) AS name
,index_id ,allocation_unit_id, object_id
FROM sys.allocation_units AS au
INNER JOIN sys.partitions AS p
ON au.container_id = p.hobt_id
AND (au.type = 1 OR au.type = 3)
UNION ALL
SELECT object_name(object_id) AS name
,index_id, allocation_unit_id, object_id
FROM sys.allocation_units AS au
INNER JOIN sys.partitions AS p
ON au.container_id = p.hobt_id
AND au.type = 2
) AS obj
ON bd.allocation_unit_id = obj.allocation_unit_id
LEFT JOIN sys.indexes i on i.object_id = obj.object_id AND i.index_id = obj.index_id
WHERE database_id = db_id() AND obj.[name] = 'IndexPageCount'
GROUP BY obj.name, obj.index_id , i.[name],i.[type_desc]
ORDER BY Buffered_Page_Count DESC
```<div class="image_block">
<a href="/wp-content/uploads/blogs/DataMgmt/-161.png?mtime=1349983070"><img alt="" src="/wp-content/uploads/blogs/DataMgmt/-161.png?mtime=1349983070" width="516" height="73" /></a>
</div>
As shown, the resulting buffered page count is 172 at this point. This page count is where we want to optimize the query and see how the indexing strategy can assist in lowering the overall page count and buffer utilization.
**Optimizing by lowering buffered page count**
To lower the page count, we essentially need to lessen the need to pull the pages that come along with the seek operation on the clustered index. This can be done by indexing the primary key and effectively covering the query by including in the nonkey columns, the resulting columns in the query, or better known as, a covering index.
Clear the buffer so we are sure we look at the new index and compare the page count in the buffer to the previous results.
```sql
DBCC DROPCLEANBUFFERS
Next, run the script below to create the nonclustered index or, covering index that consists of the key column being the primary key column of SalesOrderID and INCLUDE the DueDate, ShipDate and SunTotal columns.
CREATE INDEX IDX_SalesOrderID_COVER_ASC ON dbo.IndexPageCount (SalesOrderID) INCLUDE (DueDate,ShipDate,SubTotal)
Execute the previously used query
SELECT
hdr.DueDate
,hdr.ShipDate
,SUM(SubTotal) AS SubTotals
FROM
dbo.IndexPageCount hdr
WHERE hdr.SalesOrderID < 50000
GROUP BY
hdr.DueDate
,hdr.ShipDate
After reviewing the statistics IO from the second execution, the new covering index was utilized and showed an improvement on logical reads.
Table ‘IndexPageCount’. Scan count 1, logical reads 29, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Looking at the execution plan, we can see the new nonclustered index is effectively being utilized as well.
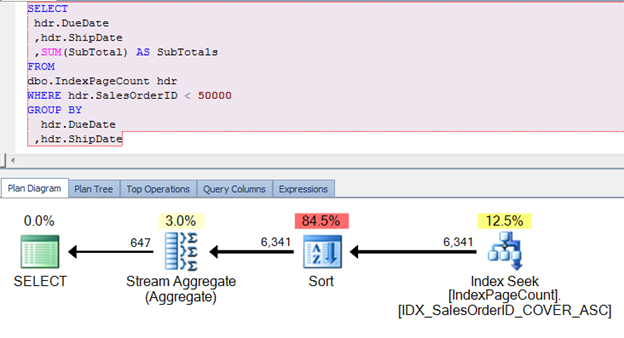
Of course, we’ve only replaced an index seek for another index seek. To see the real optimization, the IO and then equating that to review of the pages pulled into the buffer should be checked. Execute the query to review the pages in the buffer that was used previously.

As shown, the page count in the buffer is drastically lower than the previous count of 172. Based on this, we’ve optimized the execution of the query and plan but, more importantly, optimized the resources that are being used by the execution of the query.


