


Columnstore Indexes are among one of the most talked about additions in SQL Server 2012. These indexes, used properly, can have an extremely high level of impact to performance and lowering overall IO and execution time of querying data that returns a high volume result set. The only thing columnstore indexes have in common with clustered and nonclustered indexes is the use of the term “index” in the name. This article will try to give you a look into columnstore indexing from a perspective of a DBA or Developer that is familiar with traditional indexing to tune execution plan.
Storage Visualization
Clustered and Nonclustered indexes are stored based on rows on a page or RowStore. Columnstore indexes store data a bit differently. As the name insinuates, data is stored by each column or ColumnStore. This can be visualized in its simplest form below
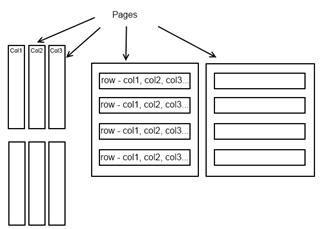
Reading data from this storage model is extremely fast comparable to row based models. However, that level of performance revolves around a mostly read environment like a data warehouse. Storage itself is enhanced by additional capabilities the columnstore index model has with compression of data. With warehouse situations and fact tables, data is commonly not unique and this also adds an extremely enhanced ability for compression.
Why is all of this important when it comes to performance? Well, Columnstore index technology is built on xVelocity in-memory analytics services, once known as Vertipaq. Vertipaq is what made PowerPivot have the ability to throw out millions of rows of data in seconds to users. xVelocity is an internal engine of its own, most commonly known in the SQL Server Analysis Services and the PowerPivot for Excel worlds, but extended to refer to columnstore index usage in SQL Server 2012. The capabilities that we, as SQL Server enthusiasts, have proved that lightning fast data retrieval can be slated as one of the largest advancements we’ve seen in data retrieval speed in past years.
Everything so far the columnstore index has to offer has referred to OLAP systems or data warehousing. Although OLAP will see the most value in columnstore indexing, OLTP systems can retain value in this indexing. With a highly transactional database, work tables or tables that have data that rapidly changes by increasing, removals and updating, will not be a candidate for a columnstore index. However, most, if not all, OLTP databases implement some internal historical table structure as a means of internal archiving, with methods to limit the number of rows in the highly transactional work tables. The historic tables may still show promise in utilizing columnstore indexing. There are some limitations that need to be considered when going this direction with OLTP though. The primary limitation: a table with a columnstore index cannot have data changed unless the columnstore index is disabled or partitioning method is implemented. Later, we will show a method to work around that.
A few other limitations in this release of the columnstore index are data type limitations. Binary, varbinary, ntext, text, image, varchar(max), nvarchar(max), uniqueidentifier, timestamp or rowversion, sql_variant, decimal, datetimeoffset, CLR types and XML, cannot be used. This restriction isn’t a new restriction in indexing. Indexing these types of data types even in clustered and nonclustered indexing has its downfalls.
Before moving into showing how to work with a columnstore index, creating columnstore indexes on a table should typically contain all the columns in the table that meet the requirements of a columnstore index. This can be hard to get a handle on when it comes to traditional and OLTP based DBAs. Creating an index that contains all the columns in a table has not been the most optimal strategy in the past. Columnstore indexing is a different type of index and based on an entirely different internal engine, xVelocity, so in terms of the columnstore index, it is best to include all the columns. The concept of this index in bed with xVelocity also prevents the traditional index maintenance and review processes you may be used to from being performed on it. In almost every scenario while working on a SQL Server 2005 or higher instance, a DBA would turn to dm_db_index_physical_stats and several other DMVs to provide us the ability to make proactive maintenance and reviews of index objects. Columnstore indexes have a different path and at this point, not much metadata is revealed but again, the same maintenance methods don’t apply either. For a great in-depth look at the metadata and even more demonstrations of digging into the columnstore index, read Joe Sack’s blog, “Exploring Columnstore Index Metadata, Segment Distribution and Elimination Behaviors”.
To show how a columnstore index can improve overall performance for querying a table in a data warehouse, download the AdventureWorksDW2012 data file and attach it to a SQL Server 2012 instance. The AdventureWorksDW2012 data file can be found on this download page.
When attaching the data file, ensure the log file that is generated automatically in the attach database wizard, is removed.
The demonstrations will work off the table, FactInternetSales and two columns, TotalProductCost and SalesAmount.
Run the following query before adding any indexes other than what was in place in the database when attached.
SET STATISTICS IO ON
SELECT TotalProductCost, SalesAmount FROM [dbo].[FactInternetSales]
Review the execution plan and the IO statistics generated from the query.

(60398 row(s) affected)
Table ‘FactInternetSales’. Scan count 1, logical reads 2062, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The IO that was generated from the query is extensive on logical reads. This in most situations will cause the query to not only run slower, but also cause IO and CPU resources to be used less efficiently.
After reviewing this query plan, in most cases a nonclustered index would be used to decrease the overall IO that is required by the query. For example, execute the create index below.
CREATE NONCLUSTERED INDEX IDX_PRODCOST_SALESAMT ON [dbo].[FactInternetSales] (TotalProductCost,SalesAmount)
Then, execute the query to retrieve TotalProductCost and SalesAmount again and review the new execution plan and IO that was generated.
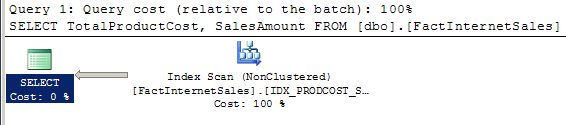
(60398 row(s) affected)
Table ‘FactInternetSales’. Scan count 1, logical reads 311, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The execution plan shows the new nonclustered index being utilized and the IO also shows a significant decrease in logical reads. This is a major improvement over the original execution plan and index use of the clustered index. A columnstore index can improve this even more.
Prepare the table for a columnstore index by dropping the nonclustered index created earlier.
DROP INDEX [FactInternetSales].IDX_PRODCOST_SALESAMT
The create columnstore index statement is similar to creating a clustered or nonclustered index. All columnstore indexes are created as nonclustered indexes and use the keyword, COLUMNSTORE in the statement.
Create a columnstore index on the FactInternetSales table by using the statement below.
CREATE NONCLUSTERED COLUMNSTORE INDEX IDX_COLSTORE_PRODCOST_SALESAMT ON [FactInternetSales] (TotalProductCost,SalesAmount)
After the columnstore index is created, execute the same query used earlier and review the new execution plan generated.
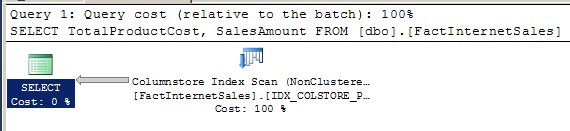
The columnstore index is now used. Review the IO statistics.
(60398 row(s) affected)
Table ‘FactInternetSales’. Scan count 1, logical reads 21, physical reads 2, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The logical reads have been lowered from 2062 to 21 with this new execution plan and use of the columnstore index. This has shown an even larger positive impact to the performance of this query by implementing a columnstore index.
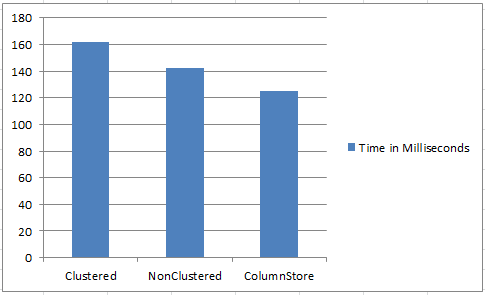
The overall time of execution in milliseconds can be seen with each index being used below. Overall, the columnstore index has proven to be more efficient for this type of query and with data that is designated for reading only requirements.
Updating Tables with Columnstore Indexes on them
There is one aspect to using a columnstore index that can be undesirable. A table that has a columnstore index on it cannot have any data altered in it. This includes UPDATE, INSERT or DELETE.
Partitioning and either disabling or removing the columnstore index can be performed to work around this. Disabling a columnstore index can be a quick way when quick fixes are needed. When disabling an index, the only way to enable the index again for the optimizer to consider it in an execution plan, is to rebuild it. Rebuild operations on an index of substantial size can take some time and cause some delays in normal data retrieval while the rebuild is executing. On smaller to mid-size tables, it is a good method to look into.
For example, a situation may arise after a data warehouse processing task that has caused some calculations to be incorrect. Often, in situations where a calculation is incorrect and the correct value has been found, an update is the quickest method to resolving the incorrect data so the business can continue to use the data effectively. With a columnstore index on the table, the update cannot be performed until the index is disabled. In the following demonstration, all the SalesAmount data with a SalesTerritoryKey of 6 requires an increase of 23%. Leave the columnstore index on the table and execute the update statement below.
UPDATE [dbo].[FactInternetSales]
SET SalesAmount = SalesAmount * .23
WHERE SalesTerritoryKey = 6
The following error will be generated from the update and no data will be changed.
Msg 35330, Level 15, State 1, Line 1
UPDATE statement failed because data cannot be updated in a table with a columnstore index. Consider disabling the columnstore index before issuing the UPDATE statement, then rebuilding the columnstore index after UPDATE is complete.
To achieve the update statement, use the ALTER INDEX statement to disable the index.
ALTER INDEX IDX_COLSTORE_PRODCOST_SALESAMT ON [dbo].[FactInternetSales] DISABLE
Execute the update statement again and the update will succeed in updating the data for SalesTerritoryKey 6.
In order to get the columnstore index enabled and available for the optimizer to utilize, the index needs to be rebuilt by using the ALTER INDEX command again with the REBUILD option this time.
ALTER INDEX IDX_COLSTORE_PRODCOST_SALESAMT ON [dbo].[FactInternetSales] REBUILD
Batch vs. Row Execution
With OLTP based systems, parallelism can be a handicap. I want to emphasis the word, “can” in that statement. It is commonly thought that if you see parallelism in your execution plan, you should work to remove it. Before we talk about this on an OLAP based system, which should never be a written rule. Each case of parallelism should be tested for overall performance. Parallelism can be a good thing and improve some queries. There is a good reason it is generated in some execution plans and that reason is, overall better performance. With OLTP, it needs to be considered as something that you need to verify it should not be removed by testing the execution plan generated for optimal performance.
With OLAP, parallelism is a friend. Typically, in an OLAP based system, you are generating an extremely large result from queries being run on SQL Server. These types of queries can be enhanced a great deal by parallelism in the execution plans. Essentially, batch processing at a CPU level occurs. The term batch in this case means, slicing a total amount of work into multiple amounts of work that still equal the total amount of work. This set of smaller amounts of work are then set to a processing resource and then run in parallel. When considering working with a large amount work to retrieve data, you can start to see the impact can be significant on helping the overall task complete faster.
The columnstore usage can benefit from parallelism the same way a simple select with other indexes can when retrieving a large amount of data. Recall that this entire scenario works from an OLAP based system. This typically means working with extremely large tables. However, in some situations, tables may not be as large and the optimizer will decide parallelism is not the best method in an execution plan over a simple execution plan that can truly only needs the utilization of one processing resource. In the AdventureWorksDW2012 database, the tables will most likely all generate execution plans that will not use parallelism due to the size of the tables. To fully show the differences in a columnstore index being used with both row execution mode and batch execution mode, a second table can be created and loaded with duplicate data.
Use the same FactInternetSales table that was used earlier. The SELECT INTO statement and GO n can be used to accomplish this quickly.
SELECT * INTO [FactInternetSales_VLT] FROM [FactInternetSales]
GO
INSERT INTO [FactInternetSales_VLT]
SELECT * FROM [FactInternetSales_VLT]
GO 10
The GO n will execute the statement in a loop with a subscript value based on the number specified after the GO. If you ran GO 4 on a table that had 60398 rows, like the FactInternetSales table, you would essentially be calculating ((((60398 * 2) * 2) * 2) * 2).
For each step, the table would multiply itself by 2.
60398 * 2 = 120796
120796 * 2 = 241592
241592 * 2 = 483184
483184 * 2 = 966368
… And so on
To show a more substantial amount of work in the execution plan with parallelism, the following query can be used.
SELECT SalesTerritoryKey, SUM(TotalProductCost), SUM(SalesAmount) FROM [dbo].[FactInternetSales_VLT]
GROUP BY SalesTerritoryKey
ORDER BY SalesTerritoryKey
This query generates the execution plan shown below

The statistics IO that was generated from this query
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
_Table ‘FactInternetSalesVLT’. Scan count 5, logical reads 131348, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The execution plan and the results are of course not optimal. The Table Scan operation in almost all instances will cause an extreme decrease in performance. As with our previous demonstration showing both a nonclustered index and a columnstore index, a nonclustered index on SalesTerritoryKey, TotalProductCost and SalesAmount would help this plan by implementing an Index Scan over the Table Scan. However, a columnstore index would benefit this plan even more as long as an execution mode of batch was utilized.
Create a columnstore index that contains all three columns used in the query.
CREATE NONCLUSTERED COLUMNSTORE INDEX IDX_COLSTORE_PRODCOST_SALESAMT ON [FactInternetSales_VLT] (SalesTerritoryKey,TotalProductCost,SalesAmount)
Execute the same query again and review the execution plan that was generated and statistics IO.

_Table ‘FactInternetSalesVLT’. Scan count 4, logical reads 116, physical reads 10, read-ahead reads 33, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
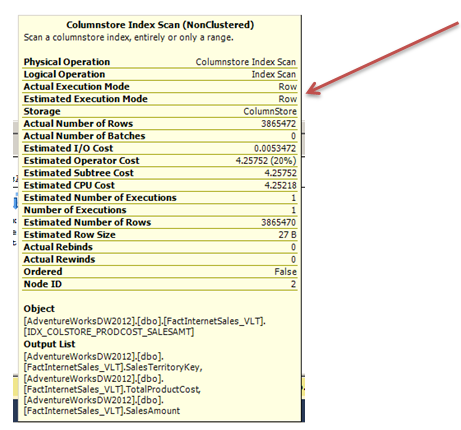
These results are much more favorable due two primary aspects of the execution plan and the actual scan on the columnstore index. With the execution plan still showing, hover over the Columnstore Index Scan operation to show the properties.

Note the execution mode shown as Batch. This is only accomplished due to the use of parallelism in the execution plan.
To run this same query using a row execution mode, use the MAXDOP query hint to force only the number of processors the plan will use to 1.
SELECT SalesTerritoryKey, SUM(TotalProductCost), SUM(SalesAmount) FROM [dbo].[FactInternetSales_VLT]
GROUP BY SalesTerritoryKey
ORDER BY SalesTerritoryKey
OPTION (MAXDOP 1)
The execution plan generated will appear identical to the previous execution plan. However, the time to generate the plan may have been observed as slightly longer. This was due to the execution mode being row in this plan. Hover the mouse over the Columnstore Index Scan and check the execution mode again.
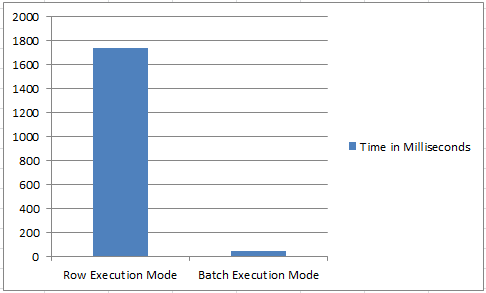
The overall execution time between the execution mode of row and batch is significant as well. In these two tests, the actually overall time spent executing the query was 1738ms for a row execution mode and 45ms for a batch execution mode.
Summary
Indexing is one of the most powerful means to enhancing the performance of retrieving data in SQL Server. At the same time, misuse of indexing can also negatively affect performance. Each type of index and definition of an index should be reviewed and considered carefully in regards to the effect it will have on storage, and as it relates to other indexes that may exist already. Columnstore indexes, as we’ve discussed, are different from the other indexing strategies SQL Server has traditionally had available. It may appear from this and other reviews of the columnstore index that every table or database would benefit from using them, but each should be considered carefully on how they will impact the databases.
This review has shown the extremely high value in columnstore indexing. Although this method of indexing and technology has a place in OLAP based databases, the value can extend into OLTP based databases where there is the ability to meet the restrictions they bring.


