


There’s been a lot of buzz about the cloud over the past years, with a lot of that attention going to IaaS and SaaS platforms, but there’s a revolution (or re-revolution) that is of even more importance, and that’s PaaS. What PaaS brings us is the ability to scale horizontally and treat CPU, memory, and storage as pools of resources that are as deep as our checkbooks allow.
Forget about virtual servers. Remember that 60 hour job with a 24 hour deadline? Built on a PaaS platform and equipped with a couple hundred dollars, you won’t even be staying late today.
Today’s post is going to share highlights from a basic file processing application. Something you would find (hopefully better written) in any random enterprise IT shop or SaaS company. It offers a web page that lets you upload files, a button to process files, a basic and poorly written list of the processed and unprocessed files, and an unattended worker. The trick is that this application was written on top of Windows Azure, so I can play tricks with time just by twisting the dial from one file processor to twenty.
The Basic File Processor
The file processing in the sample application is intended to be a sample workload. It consists of reading files completely into memory and passing them around, spinning through them one character at a time, replacing each character in the line with it’s upper case variant. Very critical stuff, very performant.
In addition to running the process via the website, I also need an unattended application that will can run the same processing function. If I owned the server, this would be a scheduled task or service. As an Azure Worker the code will be remarkably similar.
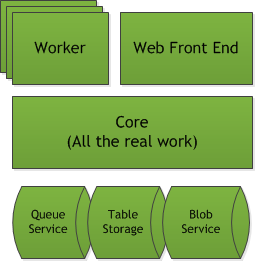
Architecture of the Processor
The two front-ends access common logic in the Core library, which is responsible for both the processing logic and interacting with storage resources. This being sample code, it is certified as working on my machine and is definitely not production ready. That being said, I did write this in a few evenings, so writing a production-ready service doesn’t have to take that long in normal workdays.
The Web Site
The website has a single MVC controller with 3 actions:
- ~/Home/Index: Displays the list of processed and unprocessed items and buttons for upload and processing
- ~/Home/AddFile: The post address for file uploads
- ~/Home/ProcessNextItem: An action to process the next queued file
public class HomeController : Controller {
IStorageLocator _storageLocator;
public HomeController() {
_storageLocator = new StorageManager("Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString");
}
public ActionResult Index() {
var store = new ItemStore(_storageLocator);
var model = new StatusViewModel() {
ProcessedItems = store.GetProcessedList(),
UnprocessedItems = store.GetUnprocessedList()
};
ViewData["file"] = TempData["file"];
return View(model);
}
[HttpPost]
public ActionResult AddFile(HttpPostedFileBase file) {
if (file != null && file.ContentLength > 0) {
var item = new FullItem() {
ResourceId = Guid.NewGuid(),
Received = DateTime.Now.ToUniversalTime(),
IsProcessed = false,
FileName = file.FileName
};
item.ReadFileFromStream(file.InputStream);
new ItemStore(_storageLocator).AddNewItem(item);
TempData["file"] = file.FileName + " uploaded and queued for processing.";
}
else {
TempData["file"] = "Processor ignores empty files, sorry.";
}
return RedirectToAction("Index");
}
[HttpGet]
public ActionResult ProcessNextItem() {
var store = new ItemStore(_storageLocator);
new ItemProcessor().ProcessNextItem(store);
return RedirectToAction("Index");
}
}
The key to all of these methods is the ItemStore and ItemProcessor class, all of the rest of the logic is basic presentation layer logic.
The Worker Role
The worker role consists of a roughly 6 line while(true) statement that asks the ItemStore to process the next item in the queue, then sleeps for 1 second.
public override void Run() {
while (true) {
var storageLocator = new StorageManager("Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString");
var store = new ItemStore(storageLocator);
new ItemProcessor().ProcessNextItem(store);
Thread.Sleep(1000);
Trace.WriteLine("Working", "Information");
}
}
Once again, the magic happens in the ItemStore and ItemProcessor instances.
The ItemStore
The ItemStore class exposes the basic methods we need execute our process:
public void AddNewItem(FullItem item) { /* More Code */ }
public FullItem RetrieveForProcessing() { /* More Code */ }
public void StoreFinishedItem(FullItem item) { /* More Code */ }
And a pair of methods for visibility:
public IEnumerable<ItemBase> GetUnprocessedList() { /* More Code */ }
public IEnumerable<ItemBase> GetProcessedList() { /* More Code */ }
Windows Azure offers a number of storage options, each with their own benefits and constraints. For this process I decided to use table storage to track the summary level information about each file processing job, blob storage to store the actual file, and the queue service for managing task execution.
public class ItemStore {
public static string RAW_BLOB_NAME = "RawItems";
public static string FINISHED_BLOB_NAME = "FinishedItems";
public static string QUEUE_NAME = "ToBeProcessed";
public static string TABLE_NAME = "Items";
ITableStore _table;
IBlobStore _rawBlob, _finishedBlob;
IQueueStore _queue;
public ItemStore(IStorageLocator storageLocator) {
_table = storageLocator.GetTable(TABLE_NAME);
_rawBlob = storageLocator.GetBlob(RAW_BLOB_NAME);
_finishedBlob = storageLocator.GetBlob(FINISHED_BLOB_NAME);
_queue = storageLocator.GetQueue(QUEUE_NAME);
}
public void AddNewItem(FullItem item) {
_rawBlob.Create(item.ResourceId, item.File);
_queue.Enqueue(item.AsSummary());
_table.Create(item.AsSummary());
}
public IEnumerable<ItemBase> GetUnprocessedList() {
return _table.GetUnprocessedItems().ToList();
}
public IEnumerable<ItemBase> GetProcessedList() {
// ?
return _table.GetProcessedItems().ToList();
}
public FullItem RetrieveForProcessing() {
FullItem rawItem = null;
var item = _queue.Dequeue();
if (item != null) {
rawItem = new FullItem(item);
rawItem.File = _rawBlob.Retrieve(item.ResourceId);
}
return rawItem;
}
public void StoreFinishedItem(FullItem item) {
_finishedBlob.Create(item.ResourceId, item.File);
_rawBlob.Delete(item.ResourceId);
_table.Update(item.AsSummary());
}
}
The ItemStore class is built to interact with interfaces for each of these resources, using a single IStorageLocator interface to get instances of those resource interfaces. The class (and application) was driven by the small set of unit tests that helped me define how i wanted the process to work and interact with the resources above.
Configurations
With all of the pieces defined, we use a pair of configurations to tell Azure how we want to deploy everything.
The first configuration defines the services we intend to package and deploy as well as the instance size and any endpoints:
<ServiceDefinition name="CloudFileProcessorService" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<WebRole name="Processor_WebRole" vmsize="Small">
<Sites>
<Site name="Web">
<Bindings>
<Binding name="Endpoint1" endpointName="Endpoint1" />
</Bindings>
</Site>
</Sites>
<Endpoints>
<InputEndpoint name="Endpoint1" protocol="http" port="80" />
</Endpoints>
<Imports>
<Import moduleName="Diagnostics" />
</Imports>
</WebRole>
<WorkerRole name="Processor_WorkerRole" vmsize="Small">
<Imports>
<Import moduleName="Diagnostics" />
</Imports>
</WorkerRole>
</ServiceDefinition>
The second configuration is applied when we deploy the instances above and tells Azure that I want to deploy 1 Processor_WebRole instance and 2 Processor_WorkerRole instances:
<ServiceConfiguration serviceName="CloudFileProcessorService" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration" osFamily="1" osVersion="*">
<Role name="Processor_WebRole">
<Instances count="1" />
<ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString" value="UseDevelopmentStorage=true" />
</ConfigurationSettings>
</Role>
<Role name="Processor_WorkerRole">
<Instances count="2" />
<ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString" value="UseDevelopmentStorage=true" />
</ConfigurationSettings>
</Role>
</ServiceConfiguration>
Note that I’m telling it to use the local development storage, which is supported by a local storage emulator. In a production configuration I would enter the service location and a generated token.
So Where’s the Magic?
So where’s the magic that makes this a distribute application instead of 3 days of overtime? It’s sprinkled throughout the system.
The architecture of this system would work just as well outside of Azure, provided I offered it stand-ins for the 3 storage resources and deployed the instances and any necessary settings accordingly. Instead of worrying about how to manage deployments and what to use for centralized queueing and storage, I can focus on building an application that simply assumes those resources are available. Is there headroom for performance improvements? Sure, but I can also choose to throw another $15/month server at it, push data to CDNs and blob storage, add caching, or even a SQL Azure instance.
This application may be fairly basic, but nothing stops us from following this same pattern for much larger applications. PaaS has removed some of the constraints we take for granted. Even applications that have to run in-house in order to standardize against a database can now consider uploading a subset of that lookup data to a table store, performing most of the heavy lifting in the cloud, then produce a few files to import back into the on-premise system. The total execution time would be longer, but being able to scale part of the job across numerous parallel instances means the actual elapsed time can actually be much shorter.
And it means when we have a 60 hour task that’s due in 24, it’s no longer an impossible situation.
The source code is available on github along with requirements and links for setting up the emulators locally.
 My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.
My roles have included accidental DBA, lone developer, systems architect, team lead, VP of Engineering, and general troublemaker. On the technical front I work in web development, distributed systems, test automation, and devop-sy areas like delivery pipelines and integration of all the auditable things.


