


Scott Stauffer (blog | twitter) asked a question on #sqlhelp a few days ago and thought I’d go into actually doing an example on the task he was trying to accomplish.
Below is a snapshot of the tweet.


In the data flow task, bring over a flat file source and configure it to use our importer connection.
Bring over a script component now and when the “Select Script Component Type” appears, select the “Transformation” option.
In the Script Transformation Editor, select our one column (default: Column 0)
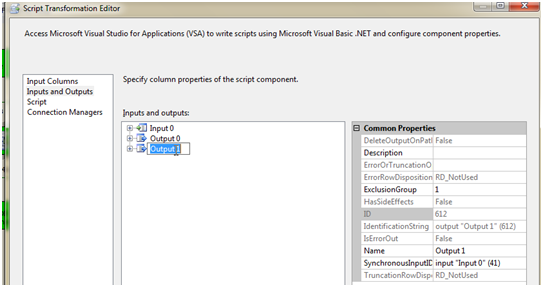
Go into the, “Input and Outputs” window and select the output.
If the names are all left as the defaults, the output will be titled, Output 0.
Change the ExclusionGroup to 1.
Add a new Output next, Output 1.
In the new output change the ExclusionGroup group to 1 as well and set the SynchronousInputID to the Input 0 ID. This will be listed in the dropdown.
Select the Script window and add into the ReadWriteVariables the variable, “global”
Go into the studio by clicking the, “design Script” next.
The code to perform the action is below. It will utilize Regular Expressions to first find the match to the unique value we need and then assign it to the variable global. In order to assign a variable in the script component without throwing Post Execute errors, we must lock the variable by using the VariableDispenser.LockOnForWrite function.
Imports System
Imports System.Data
Imports System.Math
Imports Microsoft.SqlServer.Dts.Runtime
Imports Microsoft.SqlServer.Dts.Pipeline.Wrapper
Imports Microsoft.SqlServer.Dts.Runtime.Wrapper
Imports System.Text.RegularExpressions
Public Class ScriptMain
Inherits UserComponent
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer)
If Regex.IsMatch(Row.Column0, "<[w]{4}s[w]{2}>") Then
Dim mismatch As Match
Dim pattern As New Regex("<[w]{4}s[w]{2}>")
mismatch = pattern.Match(Row.Column0)
If mismatch.Length > 0 Then
Dim var As IDTSVariables90
Me.VariableDispenser.LockOneForWrite("global", var)
var("global").Value = mismatch.Value
var.Unlock()
End If
Row.DirectRowToOutput0()
Else
Row.DirectRowToOutput1()
End If
End Sub
End Class
Drag and drop two OLEDB Destination’s into the data flow and rename them “data pump” and “headers”. We are only creating the headers destination for our testing purposes to validate the headers coming out and for later utilization if needed.
Connect the Output 1 to the data pump destination and map the column to the column in the header_split table. Connect the Output 0 to the headers destination and map the output column to the one column in the header table then.
Execute the package.
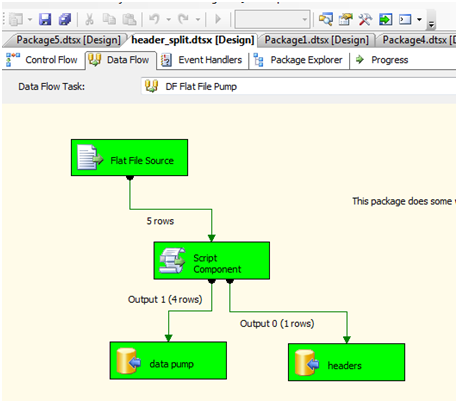
The results are showing the output that we found as a header based on our regular expression pattern match flows to the headers destination. At the same time, the data we need flows to the data pump destination.
Querying this in SSMS shows
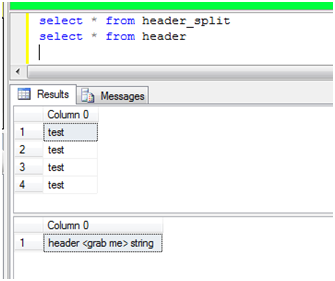
The major problem with this process is the fact we are processing row by row while putting the row under a microscope. Imagine this in a 300M row import. It wouldn’t go very well but would go if needed.
The next solution that will be much easier to implement, maintain and gain performance will follow in a second part to this post. We will utilize a script task to manipulate the file before hand, assign the variable, delete the header and import the data as needed.


