I’m jumping into the T-SQL Tuesday fun this week. The very well known, Jorge Segarra (
blog |
twitter) is
hosting the fun this time around. It is a busy week at that with SQL University writing and everything going on in the SQL Community. The SQL Server 2008 (R2) hottest, most favorite new feature topic had me wanting to throw SSIS out there once more and show off the Data Flow Engine changes. OK, the Data Flow Engine isn’t a, “New Feature” but given the redesign, I’m throwing it into the mix with the rest. This was a big, big and did I say BIG change in SSIS 2008. Being a performance freak, the changes to the Data Flow and the effective use of multi-core processors was what had me the most excited. See, with SSIS 2005, Data Flow was sent off on its merry way running execution trees with only one lonely execution thread. That meant one thread! This doesn’t help us much in a core happy world we live in. So in SSIS 2008 we had a big change to this architecture. Did I mention this was big? ###
Off to the races we go with Pipeline ParallelismWhat SSIS 2008 has given us over SSIS 2005 and the execution tree is the ability to run more than one component from the single tree. This is really a huge change. Before this change and automated thread scheduling in SSIS, we had to try making our own with designing methods. In some cases the changes in designs caused other performance problems themselves. Now with a thread pool, threads are assigned dynamically (yes, auto-magically) to components. Thread pooling is not a new concept to the computing world (and .NET framework). Thread pooling manages where and what work a set of threads will work on. When work is thrown at the pool, the work is sent off to threads that can work on it. This means multiple threads working on multiple jobs in parallel execution. Thread pooling can be done manually but with SSIS and SQL Server, we like the concept of this being controlled without us causing problems. In SSIS 2008 we were given just that automatic scheduling.The question of the hour is, does this help us with performance? The performance shines from the massive tests that have been done already and can answer the question for us. If you haven’t heard of the
ETL World Record, you need to get over there and check it out. 1 TB in 30 minutes!! Yes, on SSIS 2008 and the architecture behind it. The best way to check this out is to show the differences. Robert Sheldon also went over this test on the,
SSIS 2008 Crib sheet. Very cool write-up and recommended reading it.###
The truth is in the pipe by logging itLet’s create a package that will run some data through so we can log the execution.>
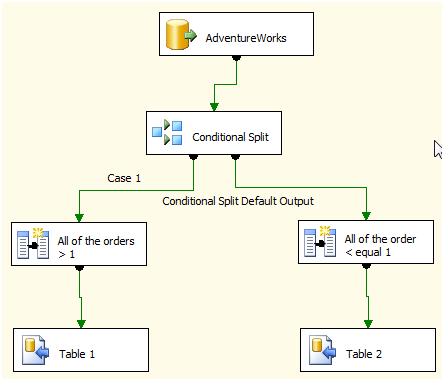
Note: the SSIS 2008 Crib sheet shows pretty much the same here. Robert did an awesome job explaining all of this. Highly recommend reading it.Steps to the test SSIS in 2005 and 2008 so we can see the execution changes and speed differences 1. In BIDS 2005, create a new package named Pipes 2005 2. Bring over an OLE DB Source and connect this source to AdventureWorks. 3. Bring in the table, Sales.SalesOrderDetail 4. Drop a Conditional Split into the Data Flow tab 5. Make the condition based on OrderQty being greater than one.
6. Next, drag and drop two Derived Column’s 7. Make one Derived column the Case 1 output by connecting the first Path to it and selecting Case 1 output 8. Make the Expression (DT_STR,3,1252)ProductID + “ for ” + (DT_STR,3,1252)OrderQty 9. Change the Data Type to DT_STR (non-unicode string)
10. Do this for the next Derived Column by connecting the remaining output path to it. 11. Name the column Under2orders and leave the Expression the same 12. Connect both Derived Columns to two unique SQL Server Destinations 13. In the SQL Server Destinations, use the same connection of AdventureWorks. Click, New to create a new table. Use the following CREATE TABLE statement: sql
CREATE TABLE
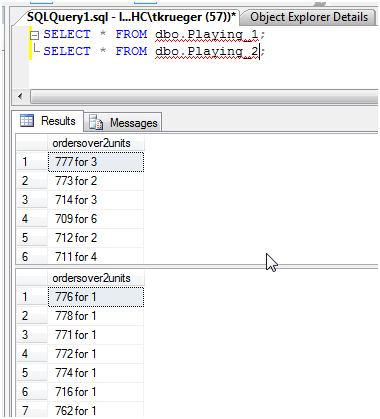
Playing_1
```
14. Use this for the second destination but name the table, [Playing_2]Our finished product should appear like below
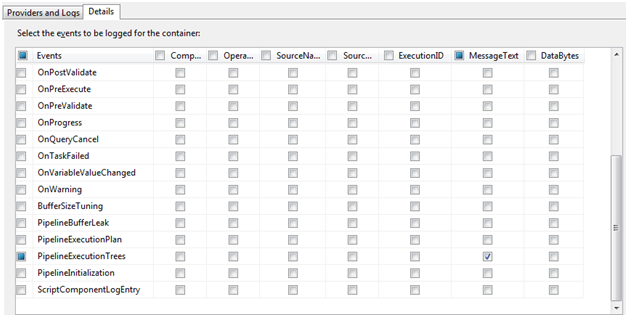
15. Next, click the menu option SSIS and select Logging 16. Select package in the Containers and add a new SSIS log provider for Text files. 17. Add a path to the new log of C:ExecutionTreeSSIS_Test2005 18. Highlight Data Flow Task to move into logging the task. 19. Click Details in the right tabs and click the Advanced button 20. Scroll down a bit and check PipelineExecutionTree. 21. Uncheck everything except MessageText
22. Click OK until out of the editors and save the package. 23. Run the package from BIDS
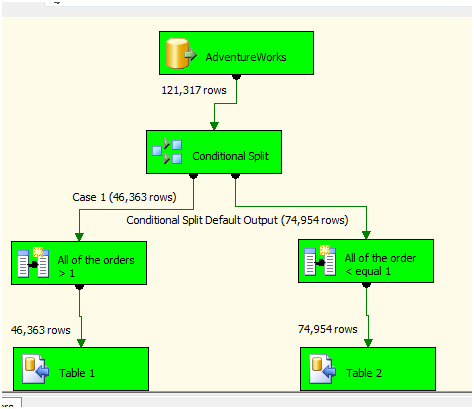
And we have our data split and loaded
Execution time was 936 MillisecondsSSIS 2005 PipelineExecutionTrees log> begin execution tree 0
output “OLE DB Source Output” (11)
input “Conditional Split Input” (17)
output “Case 1” (146)
input “Derived Column Input” (163)
output “Derived Column Output” (164)
input “SQL Server Destination Input” (61)
output “Derived Column Error Output” (165)
output “Conditional Split Default Output” (18)
input “Derived Column Input” (169)
output “Derived Column Output” (170)
input “SQL Server Destination Input” (78)
output “Derived Column Error Output” (171)
output “Conditional Split Error Output” (20)
end execution tree 0
begin execution tree 1
output “OLE DB Source Error Output” (12)
end execution tree 1We can see all of the work was primarily done in execution tree 0. 936 Milliseconds isn’t the greatest for what we just did either.Now upgrade the package to 2008 by creating a new SSIS project. Right click SSIS Packages in the Solution Explorer and select Add Existing. Browse to the package we just created in SSIS 2005 (found in your projects folder in My Documents by default). Double click the package to bring it in.
You will receive the succeeded upgrade to SSIS 2008 message. Click OK to close it and load the upgraded 2008 package.Click the SSIS option in the menu strip and select lopping. Change the path to the text file to be C:ExecutionTreeSSIS_Test2008
Save and run the packagePackage execution time for this was 640 Milliseconds. Now check the log
ExecutionTreeSSIS_Test2008
Begin path plan
Begin Path Plan 0
Call ProcessInput on component “Conditional Split” (16) for input “Conditional Split Input” (17)
Create new execution item for subpath 0
Create new execution item for subpath 1
Begin Subpath Plan 0
Create new row view for output “Case 1” (146)
Call ProcessInput on component “Derived Column” (162) for input “Derived Column Input” (163)
Create new row view for output “Derived Column Output” (164)
Call ProcessInput on component “SQL Server Destination” (45) for input “SQL Server Destination Input” (61)
End Subpath Plan 0
Begin Subpath Plan 1
Create new row view for output “Conditional Split Default Output” (18)
Call ProcessInput on component “Derived Column 1” (168) for input “Derived Column Input” (169)
Create new row view for output “Derived Column Output” (170)
Call ProcessInput on component “SQL Server Destination 1” (62) for input “SQL Server Destination Input” (78)
End Subpath Plan 1
End Path Plan 0End path planChanges we can see in the logging are the Paths and the Subpaths. This is showing the tasks being executed in the main path in parallel by using Subpaths. And our execution time was increased. ### Where’s the beef? Right there, in the Data Flow EngineThe Data Flow Engine changes are truly an enhancement that pushes SSIS to the Enterprise ETL levels. Don’t sell yourself short by dismissing the abilities of SSIS as anything less than performing at that level. > References and in-depth reading materials
Architecture of Integration ServicesTop 10 Performance and Productivity Reasons to Use SQL Server 2008 for Your Business Intelligence SolutionsSSIS 2008 Crib Sheet
About Ted Krueger (onpnt)
Ted Krueger is a SQL Server MVP and Author that has been working in development and database administration and the owner of a successful consulting business, DataMetrics Consulting. Specialties range from High Availability and Disaster / Recovery setup and testing methods down to custom assembly development for SQL Server Reporting Services. Ted blogs and is also one of the founders of LessThanDot.com technology community. Some of the articles focused on are Backup / Recovery, Security, SSIS and working on SQL Server and using all of the SQL Server features available to create stable and scalable database services.