


This is part 2 in my series on SQL window functions. In this post, we will explore using ranking functions. SQL Server support four different ranking functions which are supported in SQL Server versions 2005 and forward. All of these functions require the use of the OVER clause.
The following functions are classified as ranking functions:
• ROW_NUMBER
• RANK
• DENSE_RANK
• NTILE
Once again, the following CTE will be used as the query in all examples throughout the post:
with CTEOrders as
(select cast(1 as int) as OrderID, cast(‘3/1/2012’ as date) as OrderDate, cast(10.00 as money) as OrderAmt, ‘Joe’ as CustomerName
union select 2, ‘3/1/2012’, 11.00, ‘Sam’
union select 3, ‘3/2/2012’, 10.00, ‘Beth’
union select 4, ‘3/2/2012’, 15.00, ‘Joe’
union select 5, ‘3/2/2012’, 17.00, ‘Sam’
union select 6, ‘3/3/2012’, 12.00, ‘Joe’
union select 7, ‘3/4/2012’, 10.00, ‘Beth’
union select 8, ‘3/4/2012’, 18.00, ‘Sam’
union select 9, ‘3/4/2012’, 12.00, ‘Joe’
union select 10, ‘3/4/2012’, 11.00, ‘Beth’
union select 11, ‘3/5/2012’, 14.00, ‘Sam’
union select 12, ‘3/6/2012’, 17.00, ‘Beth’
union select 13, ‘3/6/2012’, 19.00, ‘Joe’
union select 14, ‘3/7/2012’, 13.00, ‘Beth’
union select 15, ‘3/7/2012’, 16.00, ‘Sam’
)
select OrderID
,OrderDate
,OrderAmt
,CustomerName
from CTEOrders;
ROW_NUMBER
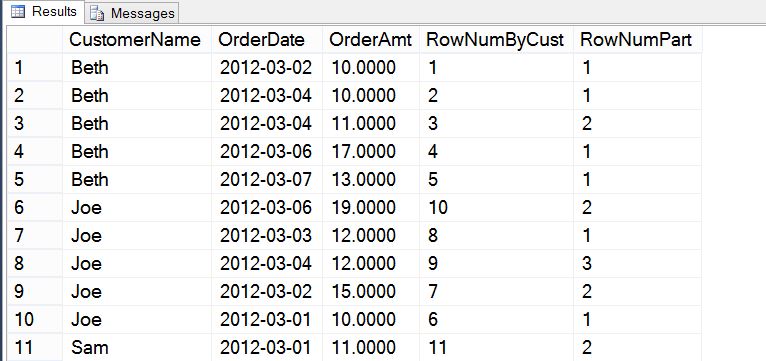
The ROW_NUMBER function will return a row number for each row within the partition based on the partition and order. This function requires the use of the ORDER BY clause. However, it is often used without the PARTITION BY clause as it will number the entire result set. If PARTITION BY is used, then the row numbering starts over within the partition. The following code shows how both of these work.
select CustomerName
,OrderDate
,OrderAmt
,ROW_NUMBER() OVER(ORDER BY CustomerName) RowNumByCust
,ROW_NUMBER() OVER(PARTITION BY OrderDate ORDER BY CustomerName) RowNumPart
from CTEOrders
order by CustomerName;
RANK and DENSE_RANK
While these are different functions with even different rules, it is easier to understand the difference when put side by side. RANK and DENSE_RANK will order the rows based on the specified partition and apply a rank or number to them. Both RANK and DENSE_RANK will assign the same rank to “ties”. For example if rows 3 and 4 have the same value in the partition, they will have the same rank. The difference is how it handles the next rank number in the series. RANK does a “true” ordering and will apply the ranking based on the number of rows and skip numbers that are ties. So, if you have a tie between the third and fourth row and the first two rows and the final row are unique the ranking is as follows: 1, 2, 3, 3, 5. As you can see, 4 is missing. DENSE_RANK keeps the tie as well, however it does not skip any numbers in the sequence. Here is the same example set based on using DENSE_RANK: 1, 2, 3, 3, 4. As with the ROW_NUMBER function, the ORDER BY is required for these functions.
select CustomerName
,OrderDate
,OrderAmt
,RANK() OVER(ORDER BY CustomerName) RankByCust
,DENSE_RANK() OVER(ORDER BY CustomerName) DenseByCust
,RANK() OVER(PARTITION BY CustomerName ORDER BY OrderDate) RankByCustDt
,DENSE_RANK() OVER(PARTITION BY CustomerName ORDER BY OrderDate) DenseByCustDt
from CTEOrders
order by CustomerName;

NTILE
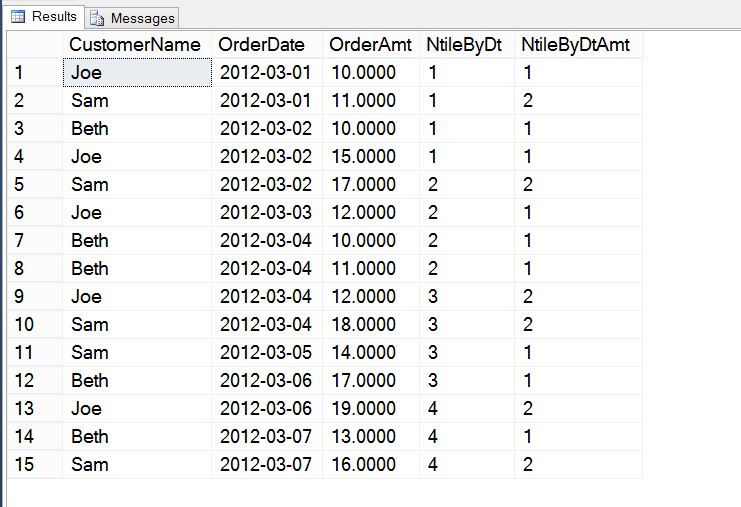
The last of the ranking functions is NTILE. NTILE groups the data into ordered and ranked groups based on the ORDER BY clause. The number of groups used in the ranking are specified in the function itself. So if you specify four groups to produce a quartile ranking, four ranked values, one through four, will be assigned to each group based on the order. In many cases, the total numbers of rows is not divisible by the number of groups chosen. For instance, if the number of groups is 4 but the total number of rows is 39, then the first three groups will return 10 rows and the final group will only return 9 rows. The function will always frontload the results so the earliest groups will have the “extra” rows. If a PARTITION BY clause is used, the NTILE ranking will applied within each partition. As with the other ranking functions, the ORDER BY clause is required to use this function.
select CustomerName
,OrderDate
,OrderAmt
,NTILE(4) OVER(ORDER BY OrderDate) NtileByDt
,NTILE(2) OVER(PARTITION BY OrderDate ORDER BY OrderAmt) NtileByDtAmt
from CTEOrders
order by OrderDate;
Up next, using aggregate functions with window functions.