


Today, I came across a question in MSDN forums “How to pick 5 random records?”. In SQL Server the only consistent way I know is to use NEWID() function in the Order By Clause.
select top 5 * from Orders order by NEWID()
This approach will always scan the entire table irrespective of number of rows requested. It retrieves each record in the table, appends a new GUID for each row, then based on that GUID it sorts the rows and presents the top 5 rows. Disadvantage here is it scans the entire table (if it’s heap) or Clustered Index.
After thinking for a while, I got an idea; If the table has a Unique column and its covered by an index, we can use that column to select the required random records and then join it with the table. This is going to improve performance.
Assume a table “Orders” with an index on column “OrderId”. In order to pick 5 random rows, we can write query like this.
;with cte as
(
select top 5 OrderID from Orders order by NEWID()
)
select t.* from cte c
inner join Orders t on t.OrderID = c.OrderID
The Inner CTE will use the index and pick the 5 random orders and outer query will get the details of those 5 random rows. By picking just the OrderIDs in CTE, we avoid the scanning of entire table. In the outer query, SQL optimizer will get the details of those rows by using lookups.
The Table we used for testing,has around 1,80,000 records. Has an Clustered index and Non-Clustered Index on the Column. For Both indexes, the only common column is “ID”. The size of these indexes is listed below.
select index_type_desc,index_level,page_count from sys.dm_db_index_physical_stats(DB_ID(),object_id('Issues'),null,null,'detailed')
```<div class="tables">
<table cellpadding="1" cellspacing="1" border="1">
<tr>
<th>
index_type_desc
</th>
<th>
index_level
</th>
<th>
page_count
</th>
</tr>
<tr>
<td>
CLUSTERED INDEX
</td>
<td>
</td>
<td>
9899
</td>
</tr>
<tr>
<td>
CLUSTERED INDEX
</td>
<td>
1
</td>
<td>
25
</td>
</tr>
<tr>
<td>
CLUSTERED INDEX
</td>
<td>
2
</td>
<td>
1
</td>
</tr>
<tr>
<td>
NONCLUSTERED INDEX
</td>
<td>
</td>
<td>
305
</td>
</tr>
<tr>
<td>
NONCLUSTERED INDEX
</td>
<td>
1
</td>
<td>
1
</td>
</tr>
</table>
</div>
Clustered Index occupied total 9925 Pages across the 3 Levels
Non Clustered Index occupied total 306 Pages across the 2 Levels
Here are the executed queries
```sql
-- Non CTE Version
SELECT TOP 5 * FROM Issue_Dump ORDER BY NEWID()
-- CTE Version
;with cte AS
(
SELECT TOP 5 [CR ID] FROM Issue_Dump ORDER BY NEWID()
)
SELECT t.* FROM cte c
INNER join Issue_Dump t ON t.[CR ID] = c.[CR ID]
Below are the recorded statistics
| Query | Logical Reads | CPU | Duration |
|---|---|---|---|
| CTE | 322 | 234 ms | 696 ms |
| Non CTE | 9926 | 7281 ms | 10193 ms |
Here is the Reason behind the Difference of Reads between the queries.
Non CTE Version Scans the Entire Clustered Index, whose size is 9925 Pages. So This query took 9925 reads,that is 1 Less than the no of reads recorded for Non CTE version.
Coming to CTE Version, It Initially Scans the entire Non CI to retrieve only 5 Ids. As Non CI occupied 306 Pages,It requires 306 reads to fetch the 5 Random Ids. Then with those 5 Ids, it fetches the details of 5 those Ids by using Clustered Index Seek. As CI spans across 3 levels, to fetch 1 record details, it will take 3 reads. For 5 records, It will take 15 reads. So combined, it will take 321(306+15) reads, which is exactly 1 less than the reads recorded.
The Extra 1 read might be because of GUIDs????
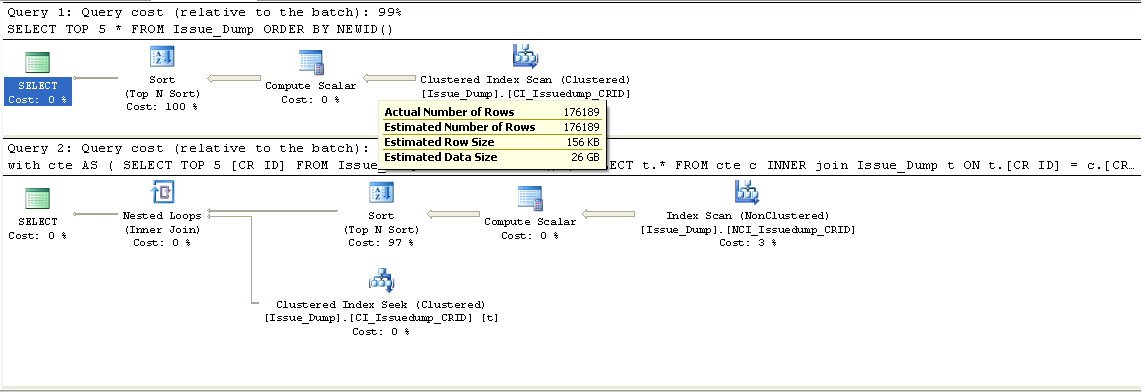
Look at the Execution Plans of the 2 queries. The CTE query outperforms the non CTE query; the CTE query chooses the Non-Clustered Index Scan(to Retrieve 5 Random OrderIDs) and a Clustered Index seek(To retrieve details of 5 records), while our initial query settled for a Clustered Index Scan.
Note: After a discussion with Brad, There will be some exceptional cases, which optimizer will choose entire Clustered Index Scan to retrieve the records
When the “Id” column is not covered by index or it is not the first key column in case of index has multiple keycolumns.
When the Random Records Sample size is too large.