


SQL Server baseline collection is an important task that is too frequently overlooked. Collecting information on how SQL Server is both providing data services and reacting to how those data services are being utilized, creates a foundation for efficient troubleshooting and predicting growth. Take a typical problem in which a customer (anyone you are providing data services to internally or externally) comes to you and states something is slow and they think it is the data services. In most situations, this would lead to a drawn out process of looking into the health of the instance directly related to the situation. What if we can first ask – and answer – the question, “What is normal performance for the period in which the data services seem to be slow?”
In reality, troubleshooting is a methodology that has an equation simply stated as – problem * identification / normal operations = solution. This means that the problem must have an identity in order for a solution to be developed. The solution cannot be sound or stable without identifying the problem. Furthering this, we can ascertain that a solution can be an evolving equation as well. A solution required, in many cases, forms a further problem in the form of changing the data services as they are at the time the initial identified problem was uncovered. This can be in the form of growth, maintenance, introduction of new variables and so on.
As we can see, this question of “what is normal” is hard to answer as an overall solution without identification and more so, a basis of what is a normal running status.
Baseline Collection
Collecting information on SQL Server has been extremely simplified since the release of 2005. This has been made possible by the exposure of data management views, system performance information and other metrics that we can easily retrieve and store for analysis. Even with this ease of retrieval, many times the development effort to set up an automated solution is foregone due to the resources available (or lack of resources). Fortunately, several SQL Server experts simplify this task further by releasing prewritten queries and distinct metrics that can be beneficial to retain for analysis over periods of time. Glenn Berry of SQLskills.com is one of those experts. Glenn has shared with us a series of diagnostic based queries that retrieve information about how SQL Server is running. These queries also expose information that can be retrieved on a time interval to base analysis over a time period. These can be used to form a baseline of how SQL Server is running. With this information being collected, one can fill in the much-needed information to the equation we discussed earlier and base a solution that is more sound and stable.
Even with the work that Glenn has done for us, there is a small amount of effort needed. In the case of the queries Glenn provides, SQL Server Integration Services (SSIS) retains much power in a rapid development platform that can be automated for later executions.
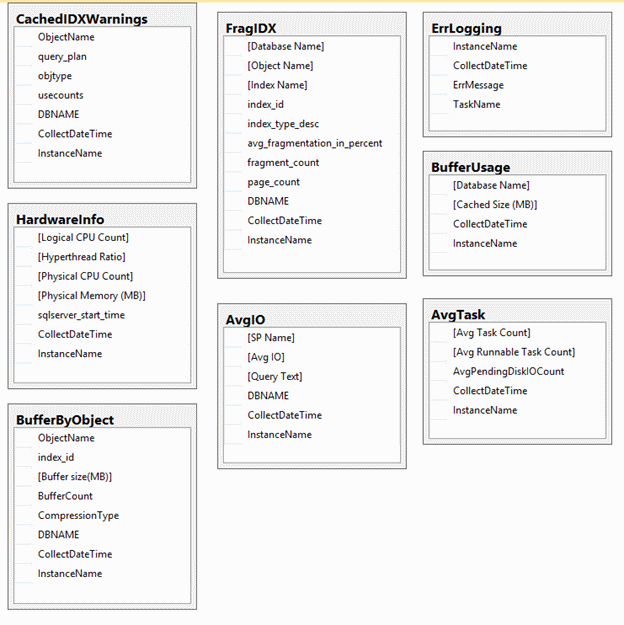
After reviewing the queries Glenn has provided, 32 distinct tables can be formed from them. Creating all these tables may seem at first to be a daunting task but it can be simplified. Working through Glenn’s SQL script, identify the segments and queries that retain value for collecting them over a period of time. Run each statement taking advantage of the SELECT INTO statement.
Note: before reading on, please ensure to always show the recognition that is deserved while using anything someone has provided to the public for use. In this case, always place the header in each area the code is used to show Glenn as the author and SQLskills.com as the supporting company.
— SQL Server 2008 R2 Diagnostic Information Queries** __**
-- SQL Server 2008 R2 Diagnostic Information Queries
-- Glenn Berry
-- April 2013
-- Last Modified: April 15, 2013
-- http://sqlserverperformance.wordpress.com/
-- http://sqlskills.com/blogs/glenn/
-- Twitter: GlennAlanBerry
-- Note: A number of these queries will only work on SQL Server 2008 R2 SP1 or later
-- They are all noted in the instructions
-- SQL Server 2008 R2 RTM was retired on July 12, 2012
— They are all noted in the instructions** __**
— SQL Server 2008 R2 RTM was retired on July 12, 2012
** __**
If an author does not provide a header such as the one above, add one stating the source, author and date.
For example: For the SQL Server 2008 R2 diagnostic information queries, the hardware information query pulling from sys.dm_os_sys_info, holds value and should be retained and monitored for change. This is evident from wanting to know how a baseline is altered by hardware changing over time. To make a table based on this query, simply add an INTO
Other considerations while creating these initial tables are the instance name, collection date and, if applicable, the database name. Without these pieces of information, a baseline cannot be formed. Make these small adjustments so the three key pieces of information are captured. Using @@SERVERNAME, GETDATE(), and DB_NAME(DB_ID()), they can be obtained quite easily.
-- Hardware information from SQL Server 2008 and 2008 R2 (Query 8) (Hardware Info)
-- (Cannot distinguish between HT and multi-core)
SELECT cpu_count AS [Logical CPU Count], hyperthread_ratio AS [Hyperthread Ratio],
cpu_count/hyperthread_ratio AS [Physical CPU Count],
physical_memory_in_bytes/1048576 AS [Physical Memory (MB)],
sqlserver_start_time --, affinity_type_desc -- (affinity_type_desc is only in 2008 R2)
,@@SERVERNAME [InstanceName]
,GETDATE() [CollectDateTime]
INTO Hardwareinfo
FROM sys.dm_os_sys_info WITH (NOLOCK) OPTION (RECOMPILE);
After performing this task for all the information to be collected, the tables will start to look much like the ones below. Ensure all the tables that are specifically designed for database-level information including the database name.
SSIS Automation
After you’ve created all the tables found to be of value, the SSIS package can be created to automate loading the data based on a schedule. In a stripped down form, the SSIS package can be executed with nothing more than the use of a series of Data Flow Tasks (DFT) and a Foreach Loop Container. The Data Flow Tasks will be a direct source to destination loading scenario except for the initial task of loading a table with the information for the instances. Loading the information about the instances is a task that requires a lookup to decide if something has changed. If nothing has changed, there is no need to insert duplicate rows, which will only make reporting off the information more difficult in the future. This lookup task would lead off the entire process.
Internally to the DFT, the process would be a source and then a lookup on the destination. This would allow the decision to be made if the data requires a new row or an update.
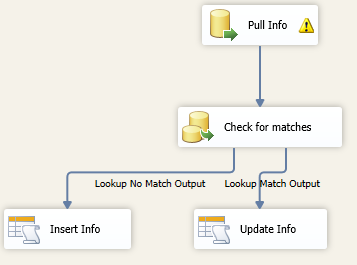
In the case above, the row is always updated. The process can also make the decision to do nothing or validate what has changed. In the case of instance information, the count of the overall rows and width of the data is typically so low, the update should not pose a performance problem.
The next series of DFTs are all similar. Group tables together so multiple queries can be executed and data moved in parallel. This will speed up the overall execution time of the SSIS package.
Take the same Hardwareinfo query from earlier. For a DFT to load this table, it would be an instance level task and not in the Foreach Loop Container.
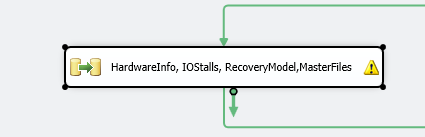
This DFT is nothing more than a direct source to destination
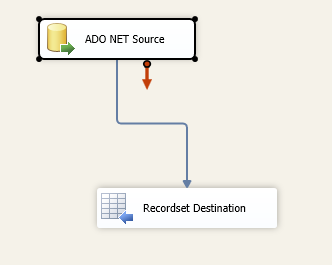
Until we get to the database specific queries, the DFT creation has been fairly simple. With database specific queries, however, we need to obtain a listing of the databases that should be evaluated and have data collected. This can be done by using the Recordset Destination populated by a source adapter based on the following query.
select name from sys.databases where name not in ('master','tempdb','model','msdb') and state_desc = 'ONLINE' and user_access_desc = 'MULTI_USER'
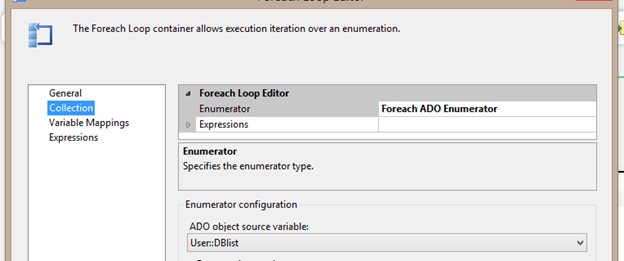
Now the Foreach Loop Container can be based on an ADO Enumerator and each internal DFT to the Foreach Loop can be executed only for the specific database that is currently allocated to a variable the Foreach Loop specifies in the object source variable. This would appear as shown below in the Foreach Loop editor.
Note: setting the MaximumErrorCount higher will prevent certain DMV queries that would error on databases from failing the entire package. This would allow the collection of databases even if one database caused an issue when the query was executed.
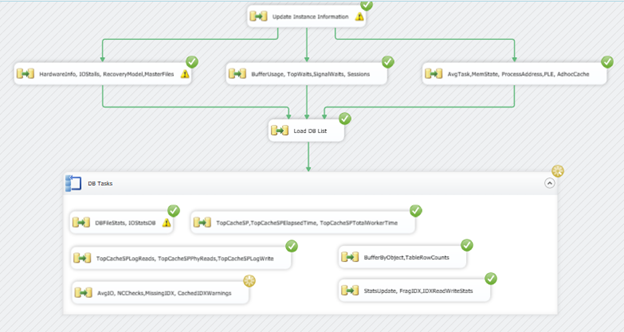
The finished SSIS Package would appear as shown below.
Baseline Reporting
Up to this point, the effort put into the baseline collection process has been minimal. Without a doubt, the reporting aspect will be a time consumption that far outweighs the SSIS or database creation to retain the information. Of course, skills may be much higher than this author’s in creating visualization of data. In fact, for the task at hand, I enlisted the expert knowledge of Jes Borland to offer a hand in making a representation of a few pieces of that data in the collection database.
Without visually being able to review the baseline data, it does not offer much value. The baseline data can be queried when needed but the overall needs of a baseline do not end with troubleshooting. We can obtain the needed information for requesting new hardware, consolidation needs and overall knowledge of data growth and business requirements that demand the need for SQL Server and the resources to evolve.
We can also obtain a quick review of how objects like indexes are being used. Indexes are evolving objects, and in that evolution, daily, weekly and monthly changes occur. Knowing how they are being used and evolving is critical to making decisions to adjust indexes so they fit the needs of the data services.
For example: looking at a segment of 5 days based on the collection in the IDXReadWriteStats table, we can (or, Jes can) design a chart as shown below on how the indexes are being read.
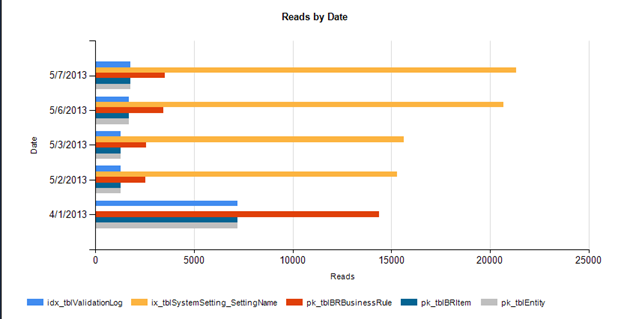
In this chart, we can quickly see on 4/1/2013, the pk_tblEntry (a master data table), was read heavy but then pulled back on reads on the other collection dates. This could show a beginning-of-the-month task that would affect the data services. Thus, the problem that could arise is the same situation where a customer comes to the team with a slow data service. If the date lands on the first and the database is directly related to the master data database, we know the entire equation to the problem and solution.
Summary
Baselines are a critical information collection process to all data services. This doesn’t stop with SQL Server but spreads to all data services. With the help and validation of resources available online in the form of scripts, blogs and articles, a solution can be development and implemented with a much lower amount of resources needed over the complete creation from the bottom, up.
If you would like to play with the SSIS Package that was written for this article and the database, you can download this compressed file. The database is SQL Server 2012. Restore the database and add the DTSX file to a new solution in SSDT 2012. Edit the variable User::SQLInstance to the instance you would like to start collecting from.


