


When replication features are used in a database, tables that are part of the publications may be altered. In particular, Merge and Transactional Replication require either a Primary Key or UNIQUEIDENTIFIER column in order to function correctly. In order to manage a change capture -not to be confused with Change Data Capture (CDC) – a unique value is required for every row in a table so replication knows what changes to replicate. Indexing these columns is a highly recommended practice as replication relies heavily on reading data from the tables that are being replicated. The execution plans that are generated from those reads should be as optimal as possible.
Unfortunately, those alterations to tables can inadvertently become a problem. What happens when a database requires an upgrade, a new deployment, or replication is removed? Alterations to the tables can cause difficulties, and it is important to understand why, and what methods exist to circumvent this problem.
Merge Replication and the GUID column
With Merge Replication, each table that is part of a publication requires a UNIQUEIDENTIFIER column. This UNIQUEIDENTIFIER column can be included in your table definition. If such a column does not exist for a table, when replication is configured a new column named rowguid will be added to the table. Transactional Replication follows the same principle but requires a unique primary key column. Again, if one is does not already exist for a table, you can create one as a surrogate key in order to replicate the table. If Merge Replication is removed, or the database is backed up or migrated, the columns will persist in the table. If the schema of the table is part of a source control that was pulled from the database, the columns will be defined in source control. However, if sp_removedbreplication is executed, or if Merge Replication is manually removed via SSMS tools, those columns that were automatically created for Merge Replication, are also removed – unless they have been indexed. In addition, if the columns were placed in the tables manually after replication was removed but code referenced them as a method to combat this problem, they will have a default constraint such as NEWSEQUENTIALID().
For example, take a table named MergeMe in database QTuner.
CREATE TABLE MergeMe (CUSTID INT IDENTITY(1,1) PRIMARY KEY, CUSTNAME NVARCHAR(50), CUSTADDR NVARCHAR(50))
GO
This table consists of a primary key and does not require any additional changes to be used in transactional replication. However, in a Merge Replication setup, this table would require a UNIQUEIDENTIFIER column. If you run the create publication wizard, you are warned about this directly after selecting the table as an article
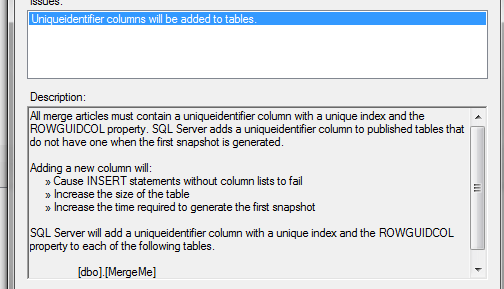
After the publication is created, review the MergeMe table definition again

As shown, the rowguid column is created in the table as well as a unique nonclustered index.
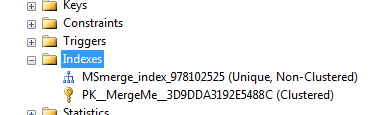
Indexing the UNIQUEIDENTIFIER
Up to this point, Merge Replication controls these objects and knows that if replication is removed, it needs to clean up after itself. But what if you are reviewing the plan cache and see an extremely poorly running query that is executing on your database engine repeatedly through the day – possibly, as often as every 60 seconds in which the agents for replication run? At this point, creating an index to cover the query would be the next step in tuning the poor-performing query.
For example, the following index may be created
CREATE INDEX IDX_ROWGUID ON MergeMe (ROWGUID ,CUSTNAME)
GO
Another common event is a code change related to the rowguid column. This happens often, and is not recommended, but it is not unheard of for a column to be directly referenced in an application, such as a linq2sql reference pulled in the schema and relies on that column being returned, or perhaps an INSERT statement was written which inserts a UNIQUEIDENTIFIER into the rowguid. The last two instances are extremely bad practice, but, as with any bad practice, they do happen.
A resulting problem from these types of modifications is that replication cannot be fully removed. For example, if we execute sp_removedbreplication on the QTuner database after creating the covering index, the following error will be thrown.
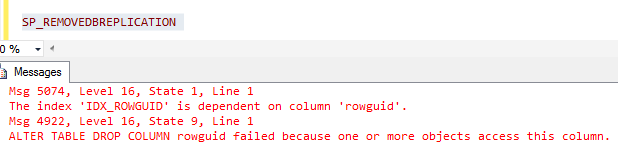
Object dependency is something we cannot get around. At this point, the only way to remove replication is to remove the index that was created on rowguid.
Another set of problems can arise from this event. Despite this error, replication can be partly removed but the application which references the rowguid column, mentioned earlier, and continues to insert directly into it. Now, the application falls under restrictions that prevent a simple change to the code base so we have to design something in the database to address this problem. Either adding the column back or leaving the column in place may occur while forcibly removing replication in the back ground. But this is where larger problems can occur.
In order to add the rowguid back, a default constraint is required for newsequantialid(). This leads to another issue in which the column cannot be dropped unless the default constraint is dropped first.
For example, take this sequence of events:
1) Indexes were dropped so replication could be removed
2) Application errors are reported on rowguid so rowguid is added back to the table
IF NOT EXISTS (SELECT 1 FROM sys.columns where Name = N'rowguid' and Object_ID = Object_ID(N'MergeMe'))
ALTER TABLE MergeMe ADD rowguid UNIQUEIDENTIFIER DEFAULT (newsequentialid())
GO
- Following a code release of the application, now the columns can be removed. What do you do if there are hundreds of them? The following script will:
- Create a list of tables in table variables
- Create a statement to drop indexes where the column is used in a key column reference
- Drop the constraints
- Drop the column
USE QTuner
GO
DECLARE @int INT = 1
DECLARE @CMD NVARCHAR(1200)
DECLARE @idxList TABLE (TableName NVARCHAR(128), IX_NAME NVARCHAR(128) NULL, ROWID INT IDENTITY(1,1), SQLCMD NVARCHAR(1200))
DECLARE @tblList TABLE (TableName NVARCHAR(128), DF_NAME NVARCHAR(128) NULL, ROWID INT IDENTITY(1,1), SQLCMD NVARCHAR(1200))
INSERT INTO @tblList (TableName) VALUES ('MergeMe')
INSERT INTO @idxList (TableName) VALUES ('MergeMe')
UPDATE list
SET DF_NAME = object_name(cols.default_object_id),
SQLCMD = 'ALTER TABLE ' + list.TableName + ' DROP CONSTRAINT ' + object_name(cols.default_object_id)
FROM @tblList list
JOIN sys.objects obj ON list.TableName = obj.Name
JOIN sys.columns cols ON obj.object_id = cols.object_id
WHERE cols.Name = 'rowguid'
WHILE @int <= (SELECT COUNT(*) FROM @tblList)
BEGIN
IF EXISTS (SELECT 1 FROM @tblList WHERE ROWID = @int AND SQLCMD IS NOT NULL)
BEGIN
SET @CMD = (SELECT SQLCMD FROM @tblList WHERE ROWID = @int)
--EXEC (@CMD)
Print @CMD
END
SET @int += 1
END
SET @int = 1
UPDATE list
SET IX_NAME = idx.Name,
SQLCMD = 'DROP INDEX ' + idx.Name + ' ON ' + list.TableName
FROM sys.indexes idx
INNER JOIN sys.index_columns cols ON idx.object_id = cols.object_id AND idx.index_id = cols.index_id
INNER JOIN sys.all_columns colName ON cols.object_id = colName.object_id AND cols.column_id = colName.column_id
JOIN @idxList list ON idx.object_id = object_id(list.TableName)
WHERE colName.name = 'rowguid'
WHILE @int <= (SELECT COUNT(*) FROM @idxList)
BEGIN
IF EXISTS (SELECT 1 FROM @idxList WHERE ROWID = @int AND SQLCMD IS NOT NULL)
BEGIN
SET @CMD = (SELECT SQLCMD FROM @idxList WHERE ROWID = @int)
--EXEC (@CMD)
Print @CMD
END
SET @int += 1
END
SET @int = 1
WHILE @int <= (SELECT COUNT(*) FROM @idxList)
BEGIN
SET @CMD = (SELECT 'ALTER TABLE ' + TableName + ' DROP COLUMN rowguid' FROM @idxList WHERE ROWID = @int)
--EXEC (@CMD)
Print @CMD
SET @int += 1
END
Note: This script does not validate for primary keys or included columns in an indexes.
Executing this script with the EXEC(@CMD) comment out, prints the following that would be executed otherwise.
ALTER TABLE MergeMe DROP CONSTRAINT DF__MergeMe__rowguid__6E8B6712
DROP INDEX IDX_ROWGUID ON MergeMe
ALTER TABLE MergeMe DROP COLUMN rowguid
Summary
As shown, there can be significant effort involved with adding replication to a database, particularly with regard to the columns that may be added to support replication, if replication is removed, misused, or managed without fully understanding the actions which occur behind the scenes. Indexing the columns that are used by replication is a valid method when the performance calls for it. Take care when creating custom indexes, as the indexes may cause problems in the future when replication changes are needed or replication is removed. Making use of extended properties and source control with comments and documentation should always be done to ease the pain for the next person that tries to work on the database.
Also, values should never be inserted into a rowguid column as part of application code or custom scripting. Those columns will be removed if replication is removed, and doing so will break any procedures or inline statements that applications are using. Rowguid columns should be used handle replication and only that task. These essential practices are even more critical when adding replication to third party databases, and it is always recommended to contact your vendor to verify that replication is supported for any third-party database.


